Python - Librerías esenciales para el análisis de datos
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Mi blog sobre Python. El contenido esta bajo la licencia BSD.
En mi artículo anterior hice una breve introducción al mundo de Python, hoy voy a detallar algunas de las librerías que son esenciales para trabajar con Python en la comunidad científica o en el análisis de datos.
Una de las grandes ventajas que ofrece Python sobre otros lenguajes de programación, además de que es que es mucho más fácil de aprender; es lo grande y prolifera que es la comunidad de desarrolladores que lo rodean; comunidad que ha contribuido con una gran variedad de librerías de primer nivel que extienden la funcionalidades del lenguaje. Vamos a poder encontrar una librería en Python para prácticamente cualquier cosa que se nos ocurra.
Algunas de las librerías que se han vuelto esenciales y ya forman casi parte del lenguaje en sí mismo son las siguientes:
Numpy
Numpy, abreviatura de Numerical Python , es el paquete fundamental para la computación científica en Python. Dispone, entre otras cosas de:
- Un objeto matriz multidimensional ndarray,rápido y eficiente.
- Funciones para realizar cálculos elemento a elemento u otras operaciones matemáticas con matrices.
- Herramientas para la lectura y escritura de los conjuntos de datos basados matrices.
- Operaciones de álgebra lineal, transformaciones de Fourier, y generación de números aleatorios.
- Herramientas de integración para conectar C, C++ y Fortran con Python
Más allá de las capacidades de procesamiento rápido de matrices que Numpy añade a Python, uno de sus propósitos principales con respecto al análisis de datos es la utilización de sus estructuras de datos como contenedores para transmitir los datos entre diferentes algoritmos. Para datos numéricos , las matrices de Numpy son una forma mucho más eficiente de almacenar y manipular datos que cualquier otra de las estructuras de datos estándar incorporadas en Python. Asimismo, librerías escritas en un lenguaje de bajo nivel, como C o Fortran, pueden operar en los datos almacenados en matrices de Numpy sin necesidad de copiar o modificar ningún dato.
Como nomenclatura general, cuando importamos la librería Numpy en nuestro programa Python se suele utilizar la siguiente:
import numpy as np
Creando matrices en Numpy
Existen varias maneras de crear matrices en Numpy, por ejemplo desde:
- Una lista o tuple de Python
- Funciones específicas para crear matrices como
arange,linspace, etc. - Archivos planos con datos, como por ejemplo archivos .csv
En Numpy tanto los vectores como las matrices se crean utilizando el objeto ndarray
#Creando un vector desde una lista de Python
vector = np.array([1, 2, 3, 4])
vector
array([1, 2, 3, 4])
#Para crear una matriz, simplemente le pasamos una lista anidada al objeto array de Numpy
matriz = np.array([[1, 2],
[3, 4]])
matriz
array([[1, 2],
[3, 4]])
#El tipo de objeto de tanto de los vectores como de las matrices es ndarray
type(vector), type(matriz)
(numpy.ndarray, numpy.ndarray)
#Los objetos ndarray de Numpy cuentan con las propiedades shape y size que nos muestran sus dimensiones.
print vector.shape, vector.size
print matriz.shape, matriz.size
(4,) 4
(2, 2) 4
Utilizando funciones para crear matrices
#arange
#La funcion arange nos facilita la creación de matrices
x = np.arange(1, 11, 1) # argumentos: start, stop, step
x
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
#linspace
#linspace nos devuelve un vector con la cantidad de muestras que le ingresemos y separados uniformamente entre sí.
np.linspace(1, 25, 25) # argumentos: start, stop, samples
array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.,
12., 13., 14., 15., 16., 17., 18., 19., 20., 21., 22.,
23., 24., 25.])
#mgrid
#Con mgrid podemos crear arrays multimensionales.
x, y = np.mgrid[0:5, 0:5]
x
array([[0, 0, 0, 0, 0],
[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4]])
y
array([[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]])
#zeros y ones
#Estas funciones nos permiten crear matrices de ceros o de unos.
np.zeros((3,3))
array([[ 0., 0., 0.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
np.ones((3,3))
array([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]])
#random.randn
#Esta funcion nos permite generar una matriz con una distribución estándar de números.
np.random.randn(5,5)
array([[ 1.39342127, 0.27553779, 1.60499887, 0.49998319, 0.70528917],
[ 0.77384386, 0.13082401, -0.94628073, 1.11938778, -0.03671148],
[-1.26643358, -0.49647634, 0.02653584, 1.69748904, 0.83353017],
[ 2.37892618, -1.21239237, 1.12638933, 1.70430737, 0.50932112],
[-0.67529314, -0.48119409, -0.6064923 , 0.03554073, -0.29703706]])
#diag
#Nos permite crear una matriz con la diagonal de números que le ingresemos.
np.diag([1,1,1])
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]])
Matplotlib
Matplotlib es la librería más popular en Python para visualizaciones y gráficos. Matplotlib puede producir gráficos de alta calidad dignos de cualquier publicación científica.
Algunas de las muchas ventajas que nos ofrece Matplotlib, incluyen:
- Es fácil de aprender.
- Soporta texto, títulos y etiquetas en formato \(\LaTeX\).
- Proporciona un gran control sobre cada uno de los elementos de las figuras, como ser su tamaño, el trazado de sus líneas, etc.
- Nos permite crear gráficos y figuras de gran calidad que pueden ser guardados en varios formatos, como ser: PNG, PDF, SVG, EPS, y PGF.
Matplotlib se integra de maravilla con IPython (ver más abajo), lo que nos proporciona un ambiente confortable para las visualizaciones y la exploración de datos interactiva.
Algunos gráficos con Matplotlib
#Generalmente se suele importar matplotlib de la siguiente forma.
import matplotlib.pyplot as plt
Ahora vamos a graficar la siguiente función.
$$f(x) = e^{-x^2}$$# Definimos nuestra función.
def f(x):
return np.exp(-x ** 2)
#Creamos un vector con los puntos que le pasaremos a la funcion previamente creada.
x = np.linspace(-1, 5, num=30)
#Representeamos la función utilizando el objeto plt de matplotlib
plt.xlabel("Eje $x$")
plt.ylabel("$f(x)$")
plt.legend()
plt.title("Funcion $f(x)$")
plt.grid(True)
fig = plt.plot(x, f(x), label="Función f(x)")
#Grafico de puntos con matplotlib
N = 100
x1 = np.random.randn(N) #creando vector x
y1 = np.random.randn(N) #creando vector x
s = 50 + 50 * np.random.randn(N) #variable para modificar el tamaño(size)
c = np.random.randn(N) #variable para modificar el color(color)
plt.scatter(x1, y1, s=s, c=c, cmap=plt.cm.Blues)
plt.grid(True)
plt.colorbar()
fig = plt.scatter(x1, y1)
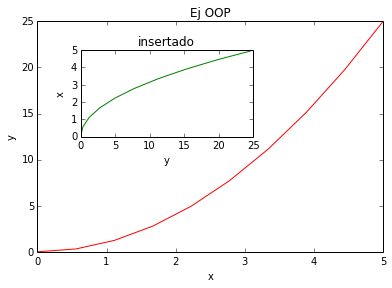
Interfase orientada a objetos de matplotlib
La idea principal con la programación orientada a objetos es que a los objetos que se pueden aplicar funciones y acciones, y ningún objeto debería tener un estado global (como en el caso de la interfase con plt que acabamos de utilizar). La verdadera ventaja de este enfoque se hace evidente cuando se crean más de una figura, o cuando una figura contiene más de una trama secundaria.
Para utilizar la API orientada a objetos comenzamos de forma similar al ejemplo anterior, pero en lugar de crear una nueva instancia global de plt, almacenamos una referencia a la recientemente creada figura en la variable fig, y a partir de ella creamos un nuevo eje ejes usando el método add_axes de la instancia Figure:
x = linspace(0, 5, 10) # Conjunto de puntos
y = x ** 2 # Funcion
fig = plt.figure()
axes1 = fig.add_axes([0.1, 0.1, 0.8, 0.8]) # Eje principal
axes2 = fig.add_axes([0.2, 0.5, 0.4, 0.3]) # Eje secundario
# Figura principal
axes1.plot(x, y, 'r')
axes1.set_xlabel('x')
axes1.set_ylabel('y')
axes1.set_title('Ej OOP')
# Insertada
axes2.plot(y, x, 'g')
axes2.set_xlabel('y')
axes2.set_ylabel('x')
axes2.set_title('insertado');
# Ejemplo con más de una figura.
fig, axes = plt.subplots(nrows=1, ncols=2)
for ax in axes:
ax.plot(x, y, 'r')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('titulo')
fig.tight_layout()
IPython
IPython promueve un ambiente de trabajo de ejecutar-explorar en contraposición al tradicional modelo de desarrollo de software de editar-compilar-ejecutar. Es decir, que el problema computacional a resolver es más visto como todo un proceso de ejecucion de tareas, en lugar del tradicional modelo de producir una respuesta(output) a una pregunta(input). IPython también provee una estrecha integración con nuestro sistema operativo, permitiendo acceder fácilmente a todos nuestros archivos desde la misma herramienta.
Algunas de las características sobresalientes de IPython son:
- Su poderoso shell interactivo.
- Notebook, su interfase web con soporte para código, texto, expresiones matemáticas, gráficos en línea y multimedia.
- Su soporte para poder realizar visualizaciones de datos en forma interactiva. IPython esta totalmente integrado con matplotlib.
- Su simple y flexible interfase para trabajar con la computación paralela.
IPython es mucho más que una librería, es todo un ambiente de trabajo que nos facilita enormemente trabajar con Python; las mismas páginas de este blog están desarrolladas con la ayuda del fantástico Notebook de IPython. (para ver el Notebook en el que se basa este artículo, visiten el siguiente enlace.)
Para más información sobre IPython y algunas de sus funciones los invito también a visitar el artículo que escribí en mi otro blog.
Pandas
Pandas es una librería open source que aporta a Python unas estructuras de datos fáciles de user y de alta performance, junto con un gran número de funciones esenciales para el análisis de datos. Con la ayuda de Pandas podemos trabajar con datos estructurados de una forma más rápida y expresiva.
Algunas de las cosas sobresalientes que nos aporta Pandas son:
- Un rápido y eficiente objeto
DataFramepara manipular datos con indexación integrada; - herramientas para la lectura y escritura de datos entre estructuras de datos rápidas y eficientes manejadas en memoria, como el
DataFrame, con la mayoría de los formatos conocidos para el manejo de datos, como ser: CSV y archivos de texto, archivos Microsoft Excel, bases de datos SQL, y el formato científico HDF5. - Proporciona una alineación inteligente de datos y un manejo integrado de los datos faltantes; con estas funciones podemos obtener una ganancia de performace en los cálculos entre
DataFramesy una fácil manipulación y ordenamiento de los datos de nuestrodata set; - Flexibilidad para manipular y redimensionar nuestro
data set, facilidad para construir tablas pivote; - La posibilidad de filtrar los datos, agregar o eliminar columnas de una forma sumamente expresiva;
- Operaciones de merge y join altamente eficientes sobre nuestros conjuntos de datos;
- Indexación jerárquica que proporciona una forma intuitiva de trabajar con datos de alta dimensión en una estructura de datos de menor dimensión ;
- Posibilidad de realizar cálculos agregados o transformaciones de datos con el poderoso motor
group byque nos permite dividir-aplicar-combinar nuestros conjuntos de datos; - combina las características de las matrices de alto rendimiento de Numpy con las flexibles capacidades de manipulación de datos de las hojas de cálculo y bases de datos relacionales (tales como SQL);
- Gran número de funcionalidades para el manejo de series de tiempo ideales para el análisis financiero;
- Todas sus funciones y estructuras de datos están optimizadas para el alto rendimiento, con las partes críticas del código escritas en Cython o C;
Estructuras de datos de Pandas
# Importando pandas
import pandas as pd
Series
# Las series son matrices de una sola dimension similares a los vectores, pero con su propio indice.
# Creando una Serie
serie = pd.Series([2, 4, -8, 3])
serie
0 2
1 4
2 -8
3 3
dtype: int64
# podemos ver tantos los índices como los valores de las Series.
print serie.values
print serie.index
[ 2 4 -8 3]
Int64Index([0, 1, 2, 3], dtype='int64')
# Creando Series con nuestros propios índices.
serie2 = pd.Series([2, 4, -8, 3], index=['d', 'b', 'a', 'c'])
serie2
d 2
b 4
a -8
c 3
dtype: int64
# Accediendo a los datos a través de los índices
print serie2['a']
print serie2[['b', 'c', 'd']]
print serie2[serie2 > 0]
-8
b 4
c 3
d 2
dtype: int64
d 2
b 4
c 3
dtype: int64
DataFrame
# El DataFrame es una estructura de datos tabular similar a las hojas de cálculo de Excel.
# Posee tanto indices de columnas como de filas.
# Creando un DataFrame.
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'year' : [2000, 2001, 2002, 2001, 2002],
'pop' : [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = pd.DataFrame(data) # Creando un DataFrame desde un diccionario
frame
| pop | state | year | |
|---|---|---|---|
| 0 | 1.5 | Ohio | 2000 |
| 1 | 1.7 | Ohio | 2001 |
| 2 | 3.6 | Ohio | 2002 |
| 3 | 2.4 | Nevada | 2001 |
| 4 | 2.9 | Nevada | 2002 |
5 rows × 3 columns
# Creando un DataFrame desde un archivo.
!cat 'dataset.csv' # ejemplo archivo csv.
pop,state,year
1.5,Ohio,2000
1.7,Ohio,2001
3.6,Ohio,2002
2.4,Nevada,2001
2.9,Nevada,2002
# Leyendo el archivo dataset.csv para crear el DataFrame
frame2 = pd.read_csv('dataset.csv', header=0)
frame2
| pop | state | year | |
|---|---|---|---|
| 0 | 1.5 | Ohio | 2000 |
| 1 | 1.7 | Ohio | 2001 |
| 2 | 3.6 | Ohio | 2002 |
| 3 | 2.4 | Nevada | 2001 |
| 4 | 2.9 | Nevada | 2002 |
5 rows × 3 columns
# Seleccionando una columna como una Serie
frame['state']
0 Ohio
1 Ohio
2 Ohio
3 Nevada
4 Nevada
Name: state, dtype: object
# Seleccionando una línea como una Serie.
frame.ix[1]
pop 1.7
state Ohio
year 2001
Name: 1, dtype: object
# Verificando las columnas
frame.columns
Index([u'pop', u'state', u'year'], dtype='object')
# Verificando los índices.
frame.index
Int64Index([0, 1, 2, 3, 4], dtype='int64')
Otras librerías dignas de mencion
Otras librerías que también son muy importantes para el análisis de datos con Python son:
SciPy
SciPy es un conjunto de paquetes donde cada uno ellos ataca un problema distinto dentro de la computación científica y el análisis numérico. Algunos de los paquetes que incluye, son:
scipy.integrate: que proporciona diferentes funciones para resolver problemas de integración numérica.scipy.linalg: que proporciona funciones para resolver problemas de álgebra lineal.scipy.optimize: para los problemas de optimización y minimización.scipy.signal: para el análisis y procesamiento de señales.scipy.sparse: para matrices dispersas y solucionar sistemas lineales dispersosscipy.stats: para el análisis de estadística y probabilidades.
Scikit-learn
Scikit-learn es una librería especializada en algoritmos para data mining y machine learning.
Algunos de los problemas que podemos resolver utilizando las herramientas de Scikit-learn, son:
- Clasificaciones: Identificar las categorías a que cada observación del conjunto de datos pertenece.
- Regresiones: Predecire el valor continuo para cada nuevo ejemplo.
- Agrupaciones: Agrupación automática de objetos similares en un conjunto.
- Reducción de dimensiones: Reducir el número de variables aleatorias a considerar.
- Selección de Modelos: Comparar, validar y elegir parámetros y modelos.
- Preprocesamiento: Extracción de características a analizar y normalización de datos.