Ipython y Spark para el analisis de datos
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Mi blog sobre Python. El contenido esta bajo la licencia BSD.
Una de las nuevas estrellas en el análisis de datos masivos es Apache Spark. Desarrollado en Scala, Apache Spark es una plataforma de computación de código abierto para el análisis y procesamiento de grandes volúmenes de datos.
Algunas de las ventajas que nos ofrece Apache Spark sobre otros frameworks, son:
- Velocidad: Sin dudas la velocidad es una de las principales fortalezas de Apache Spark, como esta diseñado para soportar el procesameinto en memoria, puede alcanzar una performance sorprendente en análisis avanzados de datos. Algunos programas escritos utilizando Apache Spark, pueden correr hasta 100x más rápido que utilizando Hadoop.
- Fácil de usar: Podemos escribir programas en Python, Scala o Java que hagan uso de las herramientas que ofrece Apache Spark; asimismo nos permite trabajar en forma interactiva (con Python o con Scala) y su API es muy fácil de aprender.
- Generalismo: El mundo del análisis de datos incluye muchos subgrupos de distinta índole, están los que hacen un análisis investigativo, los que que realizan análisis exploratorios, los que construyen sistemas de procesamientos de datos, etc. Los usuarios de cada uno de esos subgrupos, al tener objetivos distintos, suelen utilizar una gran variedad de herramientas totalmente diferentes. Apache Spark nos proporciona un gran número de herramientas de alto nivel como Spark SQL, MLlib para machine learning, GraphX, y Spark Streaming; las cuales pueden ser combinadas para crear aplicaciones multipropósito que ataquen los diferentes dominios del análisis de datos.
RDD o Resilient Distributed Datasets
En el corazón de Apache Spark se encuentran los RDDs. Los RDDs son una abstracción distribuida que le permite a los programadores realizar cómputos en memoria sobre grandes clusters de computadoras sin errores o pérdidas de información. Están especialmente diseñados para el análisis de datos interactivo (data mining) y para la aplicación de algoritmos iterativos (MapReduce). En ambos casos, mantener los datos en la memoria puede mejorar el rendimiento en una gran proporción. Para lograr la tolerancia a fallos de manera eficiente, RDDs utiliza una forma restringida de memoria compartida. Los RDDs son los suficientemente expresivos como para capturar una gran variedad de cálculos.
Instalando Apache Spark
Para instalar Apache Spark en forma local y poder comenzar a utilizarlo, pueden seguir los siguientes pasos:
- En primer lugar, necesitamos tener instalado Oracle JDK. Para instalarlo en Ubuntu podemos utilizar los siguientes comandos:
$ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-jdk7-installer
$ sudo apt-get install sbt
- Después nos descargamos la última versión de Apache Spark desde aquí
- Ahora descomprimimos el archivo:
$ tar -xvf spark-1.0.2.tgz
- Nos movemos a la carpeta recién descomprimida y realizamos la compilación de Apache Spark utilizando SBT. (tener paciencia, es sabido que Scala tarda mucho en compilar)
$ cd spark-1.0.2 $ sbt/sbt assembly
- Opcionalmente, para facilitar la utilización de Apache Spark desde la línea de comando, yo modifique mi archivo .bashrc para incluir los siguientes alias:
$ echo "alias ipyspark='IPYTHON_OPTS="notebook --pylab inline" ~/spark-1.0.2/bin/pyspark'" >> ~/.bashrc $ echo "alias pyspark='~/spark-1.0.2/bin/pyspark'" >> ~/.bashrc $ echo "alias spark='~/spark-1.0.2/bin/spark-shell'" >> ~/.bashrc
- Ahora simplemente tipeando
pysparknos abre el interprete interactivo de Python con Apache Spark, tipeandosparknos abre el interprete interactivo de Scala, y tipeandoipysparknos abre el notebook de Ipython integrado con Apache Spark!
$ ./bin/pyspark #o pyspark si creamos el alias
Ejemplo de utilización de Spark con Ipython
Ahora llegó el momento de ensuciarse las manos y probar Apache Spark, vamos a hacer el típico ejercicio de wordcounts; en este caso vamos a contar todas las palabras que posee la Biblia en su versión en inglés y vamos a ver cuantas veces aparece la palabra Dios(God). Para esto nos descargamos la versión de la Biblia en texto plano del proyecto Gutemberg.
# Comenzamos con algunos imports.
# No necesitamos importar pyspark porque ya se autoimporta como sc.
from operator import add
import pandas as pd
lineas = sc.textFile("/home/raul/spark-1.0.2/examples/data/Bible.txt") # usamos la función textFile para subir el texto a Spark
# Mapeamos las funciones para realizar la cuenta de las palabras y generamos el RDD.
cuenta = lineas.flatMap(lambda x: x.split(' ')) \
.map(lambda x: (x.replace(',' , '').upper(), 1)) \
.reduceByKey(add)
# Creamos la lista con las palabras y su respectiva frecuencia.
lista = cuenta.collect()
# Creamos un DataFrame de Pandas para facilitar el manejo de los datos.
dataframe = pd.DataFrame(lista, columns=['palabras', 'cuenta'])
# Nos quedamos solo con las palabras que hacen referencia a Dios
god = dataframe[dataframe['palabras'].apply(lambda x: x.upper() in ['GOD', 'LORD', 'JESUS', 'FATHER'])]
god
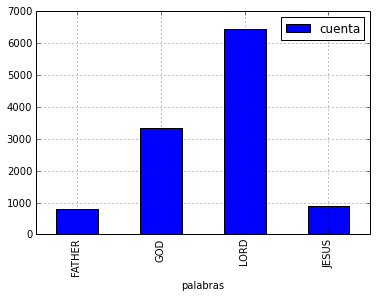
| palabras | cuenta | |
|---|---|---|
| 2867 | FATHER | 814 |
| 7329 | GOD | 3330 |
| 8902 | LORD | 6448 |
| 21404 | JESUS | 893 |
# Realizamos un gráfico de barras sobre los datos
god.set_index('palabras').plot(kind = 'bar')
<matplotlib.axes.AxesSubplot at 0x7f071e10ea10>
# Realizamos la sumatoria de las 4 palabras combinadas
god.sum()
palabras FATHERGODLORDJESUS
cuenta 11485
dtype: object
Como demuestra el ejemplo, Dios sería nombrado en la Biblia, ya sea como lord, god, jesus o father; unas 11485 veces!
Conclusión
Apache Spark es realmente una herramienta muy prometedora, con ella podemos analizar datos con un rendimiento muy alto y combinado con otras herramientas como Python, Numpy, Pandas e IPython; se convierten en un framework sumamente completo y efectivo para el análisis de grandes volúmenes de datos en forma muy sencilla.
Para más información sobre Apache Spark, pueden visitar su la sección de ejemplos de su página oficial.
Espero les haya sido de utilidad este notebook.
Saludos!!
Este post fue escrito utilizando IPython notebook. Pueden descargar este notebook o ver su version estática en nbviewer.