Machine Learning con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Mi blog sobre Python. El contenido esta bajo la licencia BSD.

Una de las ramas de estudio que cada vez esta ganando más popularidad dentro de las ciencias de la computación es el aprendizaje automático o Machine Learning. Muchos de los servicios que utilizamos en nuestro día a día como google, gmail, netflix, spotify o amazon se valen de las herramientas que les brinda el Machine Learning para alcanzar un servicio cada vez más personalizado y lograr así ventajas competitivas sobre sus rivales.
Qué es Machine Learning?
Pero, ¿qué es exactamente Machine Learning?. El Machine Learning es el diseño y estudio de las herramientas informáticas que utilizan la experiencia pasada para tomar decisiones futuras; es el estudio de programas que pueden aprenden de los datos. El objetivo fundamental del Machine Learning es generalizar, o inducir una regla desconocida a partir de ejemplos donde esa regla es aplicada. El ejemplo más típico donde podemos ver el uso del Machine Learning es en el filtrado de los correo basura o spam. Mediante la observación de miles de correos electrónicos que han sido marcados previamente como basura, los filtros de spam aprenden a clasificar los mensajes nuevos. El Machine Learning combina conceptos y técnicas de diferentes áreas del conocimiento, como las matemáticas, estadísticas y las ciencias de la computación; por tal motivo, hay muchas maneras de aprender la disciplina.
Tipos de Machine Learning
El Machine Learning tiene una amplia gama de aplicaciones, incluyendo motores de búsqueda, diagnósticos médicos, detección de fraude en el uso de tarjetas de crédito, análisis del mercado de valores, clasificación de secuencias de ADN, reconocimiento del habla y del lenguaje escrito, juegos y robótica. Pero para poder abordar cada uno de estos temas es crucial en primer lugar distingir los distintos tipos de problemas de Machine Learning con los que nos podemos encontrar.
Aprendizaje supervisado
En los problemas de aprendizaje supervisado se enseña o entrena al algoritmo a partir de datos que ya vienen etiquetados con la respuesta correcta. Cuanto mayor es el conjunto de datos más el algoritmo puede aprender sobre el tema. Una vez concluído el entrenamiento, se le brindan nuevos datos, ya sin las etiquetas de las respuestas correctas, y el algoritmo de aprendizaje utiliza la experiencia pasada que adquirió durante la etapa de entrenamiento para predecir un resultado. Esto es similar al método de aprendizaje que se utiliza en las escuelas, donde se nos enseñan problemas y las formas de resolverlos, para que luego podamos aplicar los mismos métodos en situaciones similares.
Aprendizaje no supervisado
En los problemas de aprendizaje no supervisado el algoritmo es entrenado usando un conjunto de datos que no tiene ninguna etiqueta; en este caso, nunca se le dice al algoritmo lo que representan los datos. La idea es que el algoritmo pueda encontrar por si solo patrones que ayuden a entender el conjunto de datos. El aprendizaje no supervisado es similar al método que utilizamos para aprender a hablar cuando somos bebes, en un principio escuchamos hablar a nuestros padres y no entendemos nada; pero a medida que vamos escuchando miles de conversaciones, nuestro cerebro comenzará a formar un modelo sobre cómo funciona el lenguaje y comenzaremos a reconocer patrones y a esperar ciertos sonidos.
Aprendizaje por refuerzo
En los problemas de aprendizaje por refuerzo, el algoritmo aprende observando el mundo que le rodea. Su información de entrada es el feedback o retroalimentación que obtiene del mundo exterior como respuesta a sus acciones. Por lo tanto, el sistema aprende a base de ensayo-error. Un buen ejemplo de este tipo de aprendizaje lo podemos encontrar en los juegos, donde vamos probando nuevas estrategias y vamos seleccionando y perfeccionando aquellas que nos ayudan a ganar el juego. A medida que vamos adquiriendo más practica, el efecto acumulativo del refuerzo a nuestras acciones victoriosas terminará creando una estrategia ganadora.
Sobreentrenamiento
Como mencionamos cuando definimos al Machine Learning, la idea fundamental es encontrar patrones que podamos generalizar para luego poder aplicar esta generalización sobre los casos que todavía no hemos observado y realizar predicciones. Pero también puede ocurrir que durante el entrenamiento solo descubramos casualidades en los datos que se parecen a patrones interesantes, pero que no generalicen. Esto es lo que se conoce con el nombre de sobreentrenamiento o sobreajuste.
El sobreentrenamiento es la tendencia que tienen la mayoría de los algoritmos de Machine Learning a ajustarse a unas características muy específicas de los datos de entrenamiento que no tienen relación causal con la función objetivo que estamos buscando para generalizar. El ejemplo más extremo de un modelo sobreentrenado es un modelo que solo memoriza las respuestas correctas; este modelo al ser utilizado con datos que nunca antes ha visto va a tener un rendimiento azaroso, ya que nunca logró generalizar un patrón para predecir.
Como evitar el sobreentrenamiento
Como mencionamos anteriormente, todos los modelos de Machine Learning tienen tendencia al sobreentrenamiento; es por esto que debemos aprender a convivir con el mismo y tratar de tomar medidas preventivas para reducirlo lo más posible. Las dos principales estrategias para lidiar son el sobreentrenamiento son: la retención de datos y la validación cruzada.
En el primer caso, la idea es dividir nuestro conjunto de datos, en uno o varios conjuntos de entrenamiento y otro/s conjuntos de evaluación. Es decir, que no le vamos a pasar todos nuestros datos al algoritmo durante el entrenamiento, sino que vamos a retener una parte de los datos de entrenamiento para realizar una evaluación de la efectividad del modelo. Con esto lo que buscamos es evitar que los mismos datos que usamos para entrenar sean los mismos que utilizamos para evaluar. De esta forma vamos a poder analizar con más precisión como el modelo se va comportando a medida que más lo vamos entrenando y poder detectar el punto crítico en el que el modelo deja de generalizar y comienza a sobreajustarse a los datos de entrenamiento.
La validación cruzada es un procedimiento más sofisticado que el anterior. En lugar de solo obtener una simple estimación de la efectividad de la generalización; la idea es realizar un análisis estadístico para obtener otras medidas del rendimiento estimado, como la media y la varianza, y así poder entender cómo se espera que el rendimiento varíe a través de los distintos conjuntos de datos. Esta variación es fundamental para la evaluación de la confianza en la estimación del rendimiento. La validación cruzada también hace un mejor uso de un conjunto de datos limitado; ya que a diferencia de la simple división de los datos en uno el entrenamiento y otro de evaluación; la validación cruzada calcula sus estimaciones sobre todo el conjunto de datos mediante la realización de múltiples divisiones e intercambios sistemáticos entre datos de entrenamiento y datos de evaluación.
Pasos para construir un modelo de machine learning
Construir un modelo de Machine Learning, no se reduce solo a utilizar un algoritmo de aprendizaje o utilizar una librería de Machine Learning; sino que es todo un proceso que suele involucrar los siguientes pasos:
-
Recolectar los datos. Podemos recolectar los datos desde muchas fuentes, podemos por ejemplo extraer los datos de un sitio web o obtener los datos utilizando una API o desde una base de datos. Podemos también utilizar otros dispositivos que recolectan los datos por nosotros; o utilizar datos que son de dominio público. El número de opciones que tenemos para recolectar datos no tiene fin!. Este paso parece obvio, pero es uno de los que más complicaciones trae y más tiempo consume.
-
Preprocesar los datos. Una vez que tenemos los datos, tenemos que asegurarnos que tiene el formato correcto para nutrir nuestro algoritmo de aprendizaje. Es prácticamente inevitable tener que realizar varias tareas de preprocesamiento antes de poder utilizar los datos. Igualmente este punto suele ser mucho más sencillo que el paso anterior.
-
Explorar los datos. Una vez que ya tenemos los datos y están con el formato correcto, podemos realizar un pre análisis para corregir los casos de valores faltantes o intentar encontrar a simple vista algún patrón en los mismos que nos facilite la construcción del modelo. En esta etapa suelen ser de mucha utilidad las medidas estadísticas y los gráficos en 2 y 3 dimensiones para tener una idea visual de como se comportan nuestros datos. En este punto podemos detectar valores atípicos que debamos descartar; o encontrar las características que más influencia tienen para realizar una predicción.
-
Entrenar el algoritmo. Aquí es donde comenzamos a utilizar las técnicas de Machine Learning realmente. En esta etapa nutrimos al o los algoritmos de aprendizaje con los datos que venimos procesando en las etapas anteriores. La idea es que los algoritmos puedan extraer información útil de los datos que le pasamos para luego poder hacer predicciones.
-
Evaluar el algoritmo. En esta etapa ponemos a prueba la información o conocimiento que el algoritmo obtuvo del entrenamiento del paso anterior. Evaluamos que tan preciso es el algoritmo en sus predicciones y si no estamos muy conforme con su rendimiento, podemos volver a la etapa anterior y continuar entrenando el algoritmo cambiando algunos parámetros hasta lograr un rendimiento aceptable.
-
Utilizar el modelo. En esta ultima etapa, ya ponemos a nuestro modelo a enfrentarse al problema real. Aquí también podemos medir su rendimiento, lo que tal vez nos obligue a revisar todos los pasos anteriores.
Librerías de Python para machine learning
Como siempre me gusta comentar, una de las grandes ventajas que ofrece Python sobre otros lenguajes de programación; es lo grande y prolifera que es la comunidad de desarrolladores que lo rodean; comunidad que ha contribuido con una gran variedad de librerías de primer nivel que extienden la funcionalidades del lenguaje. Para el caso de Machine Learning, las principales librerías que podemos utilizar son:
Scikit-Learn
Scikit-learn es la principal librería que existe para trabajar con Machine Learning, incluye la implementación de un gran número de algoritmos de aprendizaje. La podemos utilizar para clasificaciones, extraccion de características, regresiones, agrupaciones, reducción de dimensiones, selección de modelos, o preprocesamiento. Posee una API que es consistente en todos los modelos y se integra muy bien con el resto de los paquetes científicos que ofrece Python. Esta librería también nos facilita las tareas de evaluación, diagnostico y validaciones cruzadas ya que nos proporciona varios métodos de fábrica para poder realizar estas tareas en forma muy simple.
Statsmodels
Statsmodels es otra gran librería que hace foco en modelos estadísticos y se utiliza principalmente para análisis predictivos y exploratorios. Al igual que Scikit-learn, también se integra muy bien con el resto de los paquetes cientificos de Python. Si deseamos ajustar modelos lineales, hacer una análisis estadístico, o tal vez un poco de modelado predictivo, entonces Statsmodels es la librería ideal. Las pruebas estadísticas que ofrece son bastante amplias y abarcan tareas de validación para la mayoría de los casos.
PyMC
pyMC es un módulo de Python que implementa modelos estadísticos bayesianos, incluyendo la cadena de Markov Monte Carlo(MCMC). pyMC ofrece funcionalidades para hacer el análisis bayesiano lo mas simple posible. Incluye los modelos bayesianos, distribuciones estadísticas y herramientas de diagnostico para la covarianza de los modelos. Si queremos realizar un análisis bayesiano esta es sin duda la librería a utilizar.
NTLK
NLTK es la librería líder para el procesamiento del lenguaje natural o NLP por sus siglas en inglés. Proporciona interfaces fáciles de usar a más de 50 cuerpos y recursos léxicos, como WordNet, junto con un conjunto de bibliotecas de procesamiento de texto para la clasificación, tokenización, el etiquetado, el análisis y el razonamiento semántico.
Obviamente, aquí solo estoy listando unas pocas de las muchas librerías que existen en Python para trabajar con problemas de Machine Learning, los invito a realizar su propia investigación sobre el tema.
Algoritmos más utilizados
Los algoritmos que más se suelen utilizar en los problemas de Machine Learning son los siguientes:
- Regresión Lineal
- Regresión Logística
- Arboles de Decision
- Random Forest
- SVM o Máquinas de vectores de soporte.
- KNN o K vecinos más cercanos.
- K-means
Todos ellos se pueden aplicar a casi cualquier problema de datos y obviamente estan todos implementados por la excelente librería de Python, Scikit-learn. Veamos algunos ejemplos de ellos.
Regresión Lineal
Se utiliza para estimar los valores reales (costo de las viviendas, el número de llamadas, ventas totales, etc.) basados en variables continuas. La idea es tratar de establecer la relación entre las variables independientes y dependientes por medio de ajustar una mejor línea recta con respecto a los puntos. Esta línea de mejor ajuste se conoce como línea de regresión y esta representada por la siguiente ecuación lineal:
$$Y = \beta_{0} + \beta_{1}X_{1} + \beta_{2}X_{2} + ... + \beta_{n}X_{n}$$Veamos un pequeño ejemplo de como se implementa en Python. En este ejemplo voy a utilizar el dataset Boston que ya viene junto con Scikit-learn y es ideal para practicar con Regresiones Lineales; el mismo contiene precios de casas de varias áreas de la ciudad de Boston.
# graficos embebidos
%matplotlib inline
# importando pandas, numpy y matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# importando los datasets de sklearn
from sklearn import datasets
boston = datasets.load_boston()
boston_df = pd.DataFrame(boston.data, columns=boston.feature_names)
boston_df['TARGET'] = boston.target
boston_df.head() # estructura de nuestro dataset.
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | TARGET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
# importando el modelo de regresión lineal
from sklearn.linear_model import LinearRegression
rl = LinearRegression() # Creando el modelo.
rl.fit(boston.data, boston.target) # ajustando el modelo
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
# Lista de coeficientes B para cada X
list(zip(boston.feature_names, rl.coef_))
[('CRIM', -0.10717055656035711),
('ZN', 0.046395219529796805),
('INDUS', 0.020860239532172288),
('CHAS', 2.6885613993179822),
('NOX', -17.795758660308522),
('RM', 3.8047524602580101),
('AGE', 0.00075106170332574131),
('DIS', -1.4757587965198171),
('RAD', 0.30565503833910218),
('TAX', -0.012329346305270897),
('PTRATIO', -0.95346355469055977),
('B', 0.0093925127221893244),
('LSTAT', -0.5254666329007841)]
# haciendo las predicciones
predicciones = rl.predict(boston.data)
predicciones_df = pd.DataFrame(predicciones, columns=['Pred'])
predicciones_df.head() # predicciones de las primeras 5 lineas
| Pred | |
|---|---|
| 0 | 30.008213 |
| 1 | 25.029861 |
| 2 | 30.570232 |
| 3 | 28.608141 |
| 4 | 27.942882 |
# Calculando el desvio
np.mean(boston.target - predicciones)
5.6871503553921065e-15
Como podemos ver, el desvío del modelo es pequeño, por lo que sus resultados para este ejemplo son bastante confiables.
Regresión Logística
Los modelos lineales, también pueden ser utilizados para clasificaciones; es decir, que primero ajustamos el modelo lineal a la probabilidad de que una cierta clase o categoría ocurra y, a luego, utilizamos una función para crear un umbral en el cual especificamos el resultado de una de estas clases o categorías. La función que utiliza este modelo, no es ni más ni menos que la función logística.
$$f(x) = \frac{1}{1 + e^{-1}}$$Veamos, aquí también un pequeño ejemplo en Python.
# Creando un dataset de ejemplo
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4)
# Importando el modelo
from sklearn.linear_model import LogisticRegression
rlog = LogisticRegression() # Creando el modelo
# Dividiendo el dataset en entrenamiento y evaluacion
X_entrenamiento = X[:-200]
X_evaluacion = X[-200:]
y_entrenamiento = y[:-200]
y_evaluacion = y[-200:]
rlog.fit(X_entrenamiento, y_entrenamiento) #ajustando el modelo
# Realizando las predicciones
y_predic_entrenamiento = rlog.predict(X_entrenamiento)
y_predic_evaluacion = rlog.predict(X_evaluacion)
# Verificando la exactitud del modelo
entrenamiento = (y_predic_entrenamiento == y_entrenamiento).sum().astype(float) / y_entrenamiento.shape[0]
print("sobre datos de entrenamiento: {0:.2f}".format(entrenamiento))
evaluacion = (y_predic_evaluacion == y_evaluacion).sum().astype(float) / y_evaluacion.shape[0]
print("sobre datos de evaluación: {0:.2f}".format(evaluacion))
sobre datos de entrenamiento: 0.92
sobre datos de evaluación: 0.91
Como podemos ver en este ejemplo también nuestro modelo tiene bastante precisión clasificando las categorías de nuestro dataset.
Arboles de decisión
Los Arboles de Decision son diagramas con construcciones lógicas, muy similares a los sistemas de predicción basados en reglas, que sirven para representar y categorizar una serie de condiciones que ocurren de forma sucesiva, para la resolución de un problema. Los Arboles de Decision están compuestos por nodos interiores, nodos terminales y ramas que emanan de los nodos interiores. Cada nodo interior en el árbol contiene una prueba de un atributo, y cada rama representa un valor distinto del atributo. Siguiendo las ramas desde el nodo raíz hacia abajo, cada ruta finalmente termina en un nodo terminal creando una segmentación de los datos. Veamos aquí también un pequeño ejemplo en Python.
# Creando un dataset de ejemplo
X, y = datasets.make_classification(1000, 20, n_informative=3)
# Importando el arbol de decisión
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
ad = DecisionTreeClassifier(criterion='entropy', max_depth=5) # Creando el modelo
ad.fit(X, y) # Ajustando el modelo
#generando archivo para graficar el arbol
with open("mi_arbol.dot", 'w') as archivo_dot:
tree.export_graphviz(ad, out_file = archivo_dot)
# utilizando el lenguaje dot para graficar el arbol.
!dot -Tjpeg mi_arbol.dot -o arbol_decision.jpeg
Luego de usar el lenguaje dot para convertir nuestro arbol a formato jpeg, ya podemos ver la imagen del mismo.

# verificando la precisión
print("precisión del modelo: {0: .2f}".format((y == ad.predict(X)).mean()))
precisión del modelo: 0.96
En este ejemplo, nuestro árbol tiene una precisión del 89%. Tener en cuenta que los Arboles de Decision tienen tendencia a sobreentrenar los datos.
Random Forest
En lugar de utilizar solo un arbol para decidir, ¿por qué no utilizar todo un bosque?!!. Esta es la idea central detrás del algoritmo de Random Forest. Tarbaja construyendo una gran cantidad de arboles de decision muy poco profundos, y luego toma la clase que cada árbol eligió. Esta idea es muy poderosa en Machine Learning. Si tenemos en cuenta que un sencillo clasificador entrenado podría tener sólo el 60 por ciento de precisión, podemos entrenar un montón de clasificadores que sean por lo general acertados y luego podemos utilizar la sabiduría de todos los aprendices juntos. Con Python los podemos utilizar de la siguiente manera:
# Creando un dataset de ejemplo
X, y = datasets.make_classification(1000)
# Importando el random forest
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier() # Creando el modelo
rf.fit(X, y) # Ajustando el modelo
# verificando la precisión
print("precisión del modelo: {0: .2f}".format((y == rf.predict(X)).mean()))
precisión del modelo: 0.99
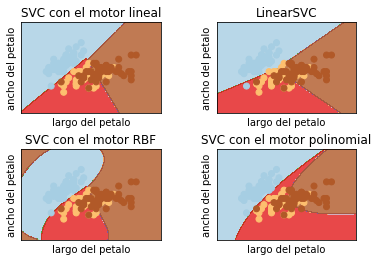
SVM o Máquinas de vectores de soporte
La idea detrás de SVM es encontrar un plano que separe los grupos dentro de los datos de la mejor forma posible. Aquí, la separación significa que la elección del plano maximiza el margen entre los puntos más cercanos en el plano; éstos puntos se denominan vectores de soporte. Pasemos al ejemplo.
# importanto SVM
from sklearn import svm
# importando el dataset iris
iris = datasets.load_iris()
X = iris.data[:, :2] # solo tomamos las primeras 2 características
y = iris.target
h = .02 # tamaño de la malla del grafico
# Creando el SVM con sus diferentes métodos
C = 1.0 # parametro de regulacion SVM
svc = svm.SVC(kernel='linear', C=C).fit(X, y)
rbf_svc = svm.SVC(kernel='rbf', gamma=0.7, C=C).fit(X, y)
poly_svc = svm.SVC(kernel='poly', degree=3, C=C).fit(X, y)
lin_svc = svm.LinearSVC(C=C).fit(X, y)
# crear el area para graficar
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# titulos de los graficos
titles = ['SVC con el motor lineal',
'LinearSVC',
'SVC con el motor RBF',
'SVC con el motor polinomial']
for i, clf in enumerate((svc, lin_svc, rbf_svc, poly_svc)):
# Realizando el gráfico, se le asigna un color a cada punto
plt.subplot(2, 2, i + 1)
plt.subplots_adjust(wspace=0.4, hspace=0.4)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)
# Graficando tambien los puntos de datos
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)
plt.xlabel('largo del petalo')
plt.ylabel('ancho del petalo')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.title(titles[i])
plt.show()
KNN o k vecinos más cercanos
Este es un método de clasificación no paramétrico, que estima el valor de la probabilidad a posteriori de que un elemento \(x\) pertenezca a una clase en particular a partir de la información proporcionada por el conjunto de prototipos. La regresión KNN se calcula simplemente tomando el promedio del punto k más cercano al punto que se está probando.
# Creando el dataset iris
iris = datasets.load_iris()
X = iris.data
y = iris.target
iris.feature_names
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
# importando KNN
from sklearn.neighbors import KNeighborsRegressor
knnr = KNeighborsRegressor(n_neighbors=10) # Creando el modelo con 10 vecinos
knnr.fit(X, y) # Ajustando el modelo
# Verificando el error medio del modelo
print("El error medio del modelo es: {:.2f}".format(np.power(y - knnr.predict(X),
2).mean()))
El error medio del modelo es: 0.02
K-means
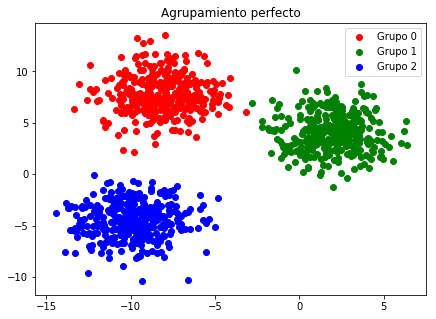
K-means es probablemente uno de los algoritmos de agrupamiento más conocidos y, en un sentido más amplio, una de las técnicas de aprendizaje no supervisado más conocidas. K-means es en realidad un algoritmo muy simple que funciona para reducir al mínimo la suma de las distancias cuadradas desde la media dentro del agrupamiento. Para hacer esto establece primero un número previamente especificado de conglomerados, K, y luego va asignando cada observación a la agrupación más cercana de acuerdo a su media. Veamos el ejemplo
# Creando el dataset
grupos, pos_correcta = datasets.make_blobs(1000, centers=3,
cluster_std=1.75)
# Graficando los grupos de datos
f, ax = plt.subplots(figsize=(7, 5))
colores = ['r', 'g', 'b']
for i in range(3):
p = grupos[pos_correcta == i]
ax.scatter(p[:,0], p[:,1], c=colores[i],
label="Grupo {}".format(i))
ax.set_title("Agrupamiento perfecto")
ax.legend()
plt.show()
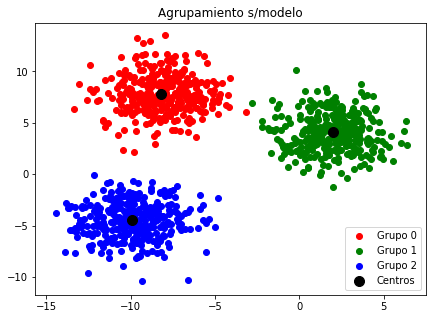
# importando KMeans
from sklearn.cluster import KMeans
# Creando el modelo
kmeans = KMeans(n_clusters=3)
kmeans.fit(grupos) # Ajustando el modelo
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=3, n_init=10, n_jobs=1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
# verificando los centros de los grupos
kmeans.cluster_centers_
array([[-9.90500465, -4.48254047],
[-8.1907267 , 7.77491011],
[ 1.9875472 , 4.07789958]])
# Graficando segun modelo
f, ax = plt.subplots(figsize=(7, 5))
colores = ['r', 'g', 'b']
for i in range(3):
p = grupos[pos_correcta == i]
ax.scatter(p[:,0], p[:,1], c=colores[i],
label="Grupo {}".format(i))
ax.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
s=100, color='black', label='Centros')
ax.set_title("Agrupamiento s/modelo")
ax.legend()
plt.show()
Con esto doy por concluída esta introducción al Machine Learning con Python, espero les sea útil.
Saludos!
Este post fue escrito utilizando IPython notebook. Pueden descargar este notebook o ver su version estática en nbviewer.