Distribuciones de probabilidad con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, análisis de datos y python. El contenido esta bajo la licencia BSD.

Introducción
Las variables aleatorias han llegado a desempeñar un papel importante en casi todos los campos de estudio: en la Física, la Química y la Ingeniería; y especialmente en las ciencias biológicas y sociales. Estas variables aleatorias son medidas y analizadas en términos de sus propiedades estadísticas y probabilísticas, de las cuales una característica subyacente es su función de distribución. A pesar de que el número potencial de distribuciones puede ser muy grande, en la práctica, un número relativamente pequeño se utilizan; ya sea porque tienen características matemáticas que las hace fáciles de usar o porque se asemejan bastante bien a una porción de la realidad, o por ambas razones combinadas.
¿Por qué es importante conocer las distribuciones?
Muchos resultados en las ciencias se basan en conclusiones que se extraen sobre una población general a partir del estudio de una muestra de esta población. Este proceso se conoce como inferencia estadística; y este tipo de inferencia con frecuencia se basa en hacer suposiciones acerca de la forma en que los datos se distribuyen, o requiere realizar alguna transformación de los datos para que se ajusten mejor a alguna de las distribuciones conocidas y estudiadas en profundidad.
Las distribuciones de probabilidad teóricas son útiles en la inferencia estadística porque sus propiedades y características son conocidas. Si la distribución real de un conjunto de datos dado es razonablemente cercana a la de una distribución de probabilidad teórica, muchos de los cálculos se pueden realizar en los datos reales utilizando hipótesis extraídas de la distribución teórica.
Graficando distribuciones
Histogramas
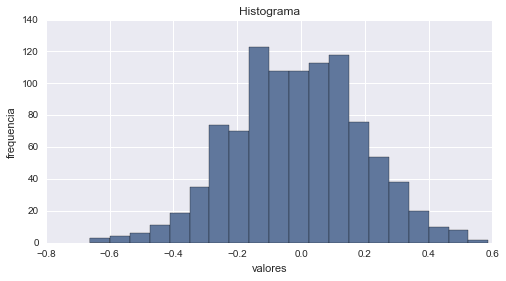
Una de las mejores maneras de describir una variable es representar los valores que aparecen en el conjunto de datos y el número de veces que aparece cada valor. La representación más común de una distribución es un histograma, que es un gráfico que muestra la frecuencia de cada valor.
En Python, podemos graficar fácilmente un histograma con la ayuda de la función hist de matplotlib, simplemente debemos pasarle los datos y la cantidad de contenedores en los que queremos dividirlos. Por ejemplo, podríamos graficar el histograma de una distribución normal del siguiente modo.
Ver Código
# <!-- collapse=True -->
# importando modulos necesarios
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
import seaborn as sns
np.random.seed(2016) # replicar random
# parametros esteticos de seaborn
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
# Graficando histograma
mu, sigma = 0, 0.2 # media y desvio estandar
datos = np.random.normal(mu, sigma, 1000) #creando muestra de datos
# histograma de distribución normal.
cuenta, cajas, ignorar = plt.hist(datos, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma')
plt.show()
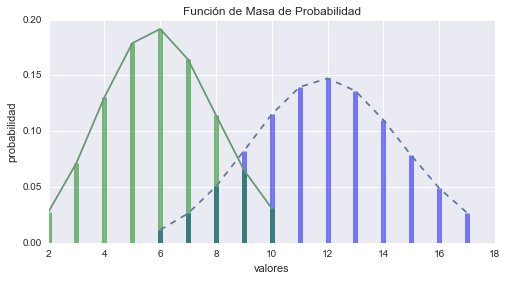
Función de Masa de Probabilidad
Otra forma de representar a las distribuciones discretas es utilizando su Función de Masa de Probabilidad o FMP, la cual relaciona cada valor con su probabilidad en lugar de su frecuencia como vimos anteriormente. Esta función es normalizada de forma tal que el valor total de probabilidad sea 1. La ventaja que nos ofrece utilizar la FMP es que podemos comparar dos distribuciones sin necesidad de ser confundidos por las diferencias en el tamaño de las muestras. También debemos tener en cuenta que FMP funciona bien si el número de valores es pequeño; pero a medida que el número de valores aumenta, la probabilidad asociada a cada valor se hace cada vez más pequeña y el efecto del ruido aleatorio aumenta. Veamos un ejemplo con Python.
# Graficando FMP
n, p = 30, 0.4 # parametros de forma de la distribución binomial
n_1, p_1 = 20, 0.3 # parametros de forma de la distribución binomial
x = np.arange(stats.binom.ppf(0.01, n, p),
stats.binom.ppf(0.99, n, p))
x_1 = np.arange(stats.binom.ppf(0.01, n_1, p_1),
stats.binom.ppf(0.99, n_1, p_1))
fmp = stats.binom.pmf(x, n, p) # Función de Masa de Probabilidad
fmp_1 = stats.binom.pmf(x_1, n_1, p_1) # Función de Masa de Probabilidad
plt.plot(x, fmp, '--')
plt.plot(x_1, fmp_1)
plt.vlines(x, 0, fmp, colors='b', lw=5, alpha=0.5)
plt.vlines(x_1, 0, fmp_1, colors='g', lw=5, alpha=0.5)
plt.title('Función de Masa de Probabilidad')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
Función de Distribución Acumulada
Si queremos evitar los problemas que se generan con FMP cuando el número de valores es muy grande, podemos recurrir a utilizar la Función de Distribución Acumulada o FDA, para representar a nuestras distribuciones, tanto discretas como continuas. Esta función relaciona los valores con su correspondiente percentil; es decir que va a describir la probabilidad de que una variable aleatoria X sujeta a cierta ley de distribución de probabilidad se sitúe en la zona de valores menores o iguales a x.
# Graficando Función de Distribución Acumulada con Python
x_1 = np.linspace(stats.norm(10, 1.2).ppf(0.01),
stats.norm(10, 1.2).ppf(0.99), 100)
fda_binom = stats.binom.cdf(x, n, p) # Función de Distribución Acumulada
fda_normal = stats.norm(10, 1.2).cdf(x_1) # Función de Distribución Acumulada
plt.plot(x, fda_binom, '--', label='FDA binomial')
plt.plot(x_1, fda_normal, label='FDA nomal')
plt.title('Función de Distribución Acumulada')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.legend(loc=4)
plt.show()

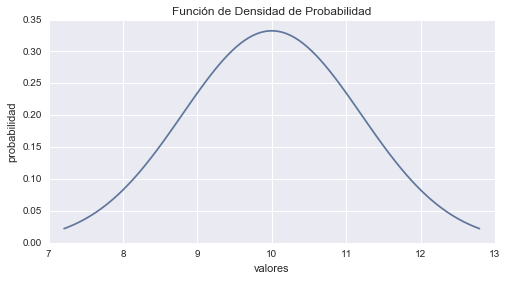
Función de Densidad de Probabilidad
Por último, el equivalente a la FMP para distribuciones continuas es la Función de Densidad de Probabilidad o FDP. Esta función es la derivada de la Función de Distribución Acumulada. Por ejemplo, para la distribución normal que graficamos anteriormente, su FDP es la siguiente. La típica forma de campana que caracteriza a esta distribución.
# Graficando Función de Densidad de Probibilidad con Python
FDP_normal = stats.norm(10, 1.2).pdf(x_1) # FDP
plt.plot(x_1, FDP_normal, label='FDP nomal')
plt.title('Función de Densidad de Probabilidad')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
Distribuciones
Ahora que ya conocemos como podemos hacer para representar a las distribuciones; pasemos a analizar cada una de ellas en más detalle para conocer su forma, sus principales aplicaciones y sus propiedades. Comencemos por las distribuciones discretas.
Distribuciones Discretas
Las distribuciones discretas son aquellas en las que la variable puede tomar solo algunos valores determinados. Los principales exponentes de este grupo son las siguientes:
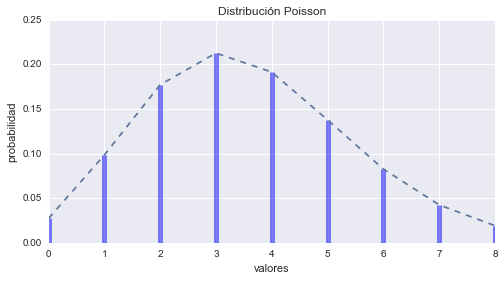
Distribución Poisson
La Distribución Poisson esta dada por la formula:
$$p(r; \mu) = \frac{\mu^r e^{-\mu}}{r!}$$En dónde \(r\) es un entero (\(r \ge 0\)) y \(\mu\) es un número real positivo. La Distribución Poisson describe la probabilidad de encontrar exactamente \(r\) eventos en un lapso de tiempo si los acontecimientos se producen de forma independiente a una velocidad constante \(\mu\). Es una de las distribuciones más utilizadas en estadística con varias aplicaciones; como por ejemplo describir el número de fallos en un lote de materiales o la cantidad de llegadas por hora a un centro de servicios.
En Python la podemos generar fácilmente con la ayuda de scipy.stats, paquete que utilizaremos para representar a todas las restantes distribuciones a lo largo de todo el artículo.
# Graficando Poisson
mu = 3.6 # parametro de forma
poisson = stats.poisson(mu) # Distribución
x = np.arange(poisson.ppf(0.01),
poisson.ppf(0.99))
fmp = poisson.pmf(x) # Función de Masa de Probabilidad
plt.plot(x, fmp, '--')
plt.vlines(x, 0, fmp, colors='b', lw=5, alpha=0.5)
plt.title('Distribución Poisson')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = poisson.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Poisson')
plt.show()
Distribución Binomial
La Distribución Binomial esta dada por la formula:
$$p(r; N, p) = \left(\begin{array}{c} N \\ r \end{array}\right) p^r(1 - p)^{N - r} $$En dónde \(r\) con la condición \(0 \le r \le N\) y el parámetro \(N\) (\(N > 0\)) son enteros; y el parámetro \(p\) (\(0 \le p \le 1\)) es un número real. La Distribución Binomial describe la probabilidad de exactamente \(r\) éxitos en \(N\) pruebas si la probabilidad de éxito en una sola prueba es \(p\).
# Graficando Binomial
N, p = 30, 0.4 # parametros de forma
binomial = stats.binom(N, p) # Distribución
x = np.arange(binomial.ppf(0.01),
binomial.ppf(0.99))
fmp = binomial.pmf(x) # Función de Masa de Probabilidad
plt.plot(x, fmp, '--')
plt.vlines(x, 0, fmp, colors='b', lw=5, alpha=0.5)
plt.title('Distribución Binomial')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = binomial.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Binomial')
plt.show()
Distribución Geométrica
La Distribución Geométrica esta dada por la formula:
$$p(r; p) = p(1- p)^{r-1} $$En dónde \(r \ge 1\) y el parámetro \(p\) (\(0 \le p \le 1\)) es un número real. La Distribución Geométrica expresa la probabilidad de tener que esperar exactamente \(r\) pruebas hasta encontrar el primer éxito si la probabilidad de éxito en una sola prueba es \(p\). Por ejemplo, en un proceso de selección, podría definir el número de entrevistas que deberíamos realizar antes de encontrar al primer candidato aceptable.
# Graficando Geométrica
p = 0.3 # parametro de forma
geometrica = stats.geom(p) # Distribución
x = np.arange(geometrica.ppf(0.01),
geometrica.ppf(0.99))
fmp = geometrica.pmf(x) # Función de Masa de Probabilidad
plt.plot(x, fmp, '--')
plt.vlines(x, 0, fmp, colors='b', lw=5, alpha=0.5)
plt.title('Distribución Geométrica')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()

# histograma
aleatorios = geometrica.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Geométrica')
plt.show()
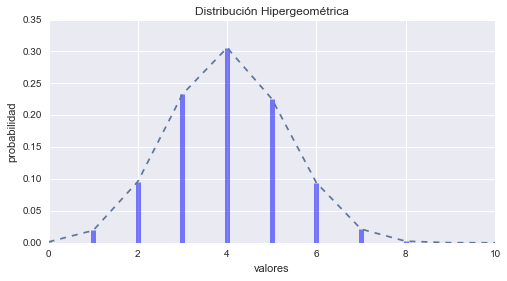
Distribución Hipergeométrica
La Distribución Hipergeométrica esta dada por la formula:
$$p(r; n, N, M) = \frac{\left(\begin{array}{c} M \\ r \end{array}\right)\left(\begin{array}{c} N - M\\ n -r \end{array}\right)}{\left(\begin{array}{c} N \\ n \end{array}\right)} $$En dónde el valor de \(r\) esta limitado por \(\max(0, n - N + M)\) y \(\min(n, M)\) inclusive; y los parámetros \(n\) (\(1 \le n \le N\)), \(N\) (\(N \ge 1\)) y \(M\) (\(M \ge 1\)) son todos números enteros. La Distribución Hipergeométrica describe experimentos en donde se seleccionan los elementos al azar sin reemplazo (se evita seleccionar el mismo elemento más de una vez). Más precisamente, supongamos que tenemos \(N\) elementos de los cuales \(M\) tienen un cierto atributo (y \(N - M\) no tiene). Si escogemos \(n\) elementos al azar sin reemplazo, \(p(r)\) es la probabilidad de que exactamente \(r\) de los elementos seleccionados provienen del grupo con el atributo.
# Graficando Hipergeométrica
M, n, N = 30, 10, 12 # parametros de forma
hipergeometrica = stats.hypergeom(M, n, N) # Distribución
x = np.arange(0, n+1)
fmp = hipergeometrica.pmf(x) # Función de Masa de Probabilidad
plt.plot(x, fmp, '--')
plt.vlines(x, 0, fmp, colors='b', lw=5, alpha=0.5)
plt.title('Distribución Hipergeométrica')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = hipergeometrica.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Hipergeométrica')
plt.show()
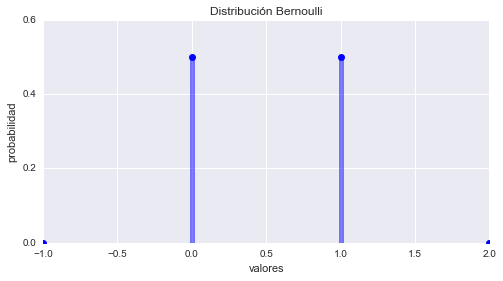
Distribución de Bernoulli
La Distribución de Bernoulli esta dada por la formula:
$$p(r;p) = \left\{ \begin{array}{ll} 1 - p = q & \mbox{si } r = 0 \ \mbox{(fracaso)}\\ p & \mbox{si } r = 1 \ \mbox{(éxito)} \end{array} \right.$$En dónde el parámetro \(p\) es la probabilidad de éxito en un solo ensayo, la probabilidad de fracaso por lo tanto va a ser \(1 - p\) (muchas veces expresada como \(q\)). Tanto \(p\) como \(q\) van a estar limitados al intervalo de cero a uno. La Distribución de Bernoulli describe un experimento probabilístico en donde el ensayo tiene dos posibles resultados, éxito o fracaso. Desde esta distribución se pueden deducir varias Funciones de Densidad de Probabilidad de otras distribuciones que se basen en una serie de ensayos independientes.
# Graficando Bernoulli
p = 0.5 # parametro de forma
bernoulli = stats.bernoulli(p)
x = np.arange(-1, 3)
fmp = bernoulli.pmf(x) # Función de Masa de Probabilidad
fig, ax = plt.subplots()
ax.plot(x, fmp, 'bo')
ax.vlines(x, 0, fmp, colors='b', lw=5, alpha=0.5)
ax.set_yticks([0., 0.2, 0.4, 0.6])
plt.title('Distribución Bernoulli')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = bernoulli.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Bernoulli')
plt.show()
Distribuciones continuas
Ahora que ya conocemos las principales distribuciones discretas, podemos pasar a describir a las distribuciones continuas; en ellas a diferencia de lo que veíamos antes, la variable puede tomar cualquier valor dentro de un intervalo específico. Dentro de este grupo vamos a encontrar a las siguientes:
Distribución de Normal
La Distribución Normal, o también llamada Distribución de Gauss, es aplicable a un amplio rango de problemas, lo que la convierte en la distribución más utilizada en estadística; esta dada por la formula:
$$p(x;\mu, \sigma^2) = \frac{1}{\sigma \sqrt{2 \pi}} e^{\frac{-1}{2}\left(\frac{x - \mu}{\sigma} \right)^2} $$En dónde \(\mu\) es el parámetro de ubicación, y va a ser igual a la media aritmética y \(\sigma^2\) es el desvío estándar. Algunos ejemplos de variables asociadas a fenómenos naturales que siguen el modelo de la Distribución Normal son:
- características morfológicas de individuos, como la estatura;
- características sociológicas, como el consumo de cierto producto por un mismo grupo de individuos;
- características psicológicas, como el cociente intelectual;
- nivel de ruido en telecomunicaciones;
- errores cometidos al medir ciertas magnitudes;
- etc.
# Graficando Normal
mu, sigma = 0, 0.2 # media y desvio estandar
normal = stats.norm(mu, sigma)
x = np.linspace(normal.ppf(0.01),
normal.ppf(0.99), 100)
fp = normal.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución Normal')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = normal.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Normal')
plt.show()
Distribución Uniforme
La Distribución Uniforme es un caso muy simple expresada por la función:
$$f(x; a, b) = \frac{1}{b -a} \ \mbox{para} \ a \le x \le b $$Su función de distribución esta entonces dada por:
$$ p(x;a, b) = \left\{ \begin{array}{ll} 0 & \mbox{si } x \le a \\ \frac{x-a}{b-a} & \mbox{si } a \le x \le b \\ 1 & \mbox{si } b \le x \end{array} \right. $$Todos los valore tienen prácticamente la misma probabilidad.
# Graficando Uniforme
uniforme = stats.uniform()
x = np.linspace(uniforme.ppf(0.01),
uniforme.ppf(0.99), 100)
fp = uniforme.pdf(x) # Función de Probabilidad
fig, ax = plt.subplots()
ax.plot(x, fp, '--')
ax.vlines(x, 0, fp, colors='b', lw=5, alpha=0.5)
ax.set_yticks([0., 0.2, 0.4, 0.6, 0.8, 1., 1.2])
plt.title('Distribución Uniforme')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = uniforme.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Uniforme')
plt.show()
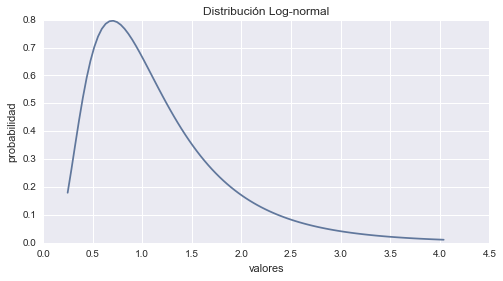
Distribución de Log-normal
La Distribución Log-normal esta dada por la formula:
$$p(x;\mu, \sigma) = \frac{1}{ x \sigma \sqrt{2 \pi}} e^{\frac{-1}{2}\left(\frac{\ln x - \mu}{\sigma} \right)^2} $$En dónde la variable \(x > 0\) y los parámetros \(\mu\) y \(\sigma > 0\) son todos números reales. La Distribución Log-normal es aplicable a variables aleatorias que están limitadas por cero, pero tienen pocos valores grandes. Es una distribución con asimetría positiva. Algunos de los ejemplos en que la solemos encontrar son:
- El peso de los adultos.
- La concentración de los minerales en depósitos.
- Duración de licencia por enfermedad.
- Distribución de riqueza
- Tiempos muertos de maquinarias.
# Graficando Log-Normal
sigma = 0.6 # parametro
lognormal = stats.lognorm(sigma)
x = np.linspace(lognormal.ppf(0.01),
lognormal.ppf(0.99), 100)
fp = lognormal.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución Log-normal')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
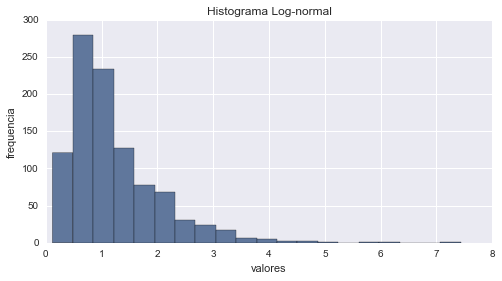
# histograma
aleatorios = lognormal.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Log-normal')
plt.show()
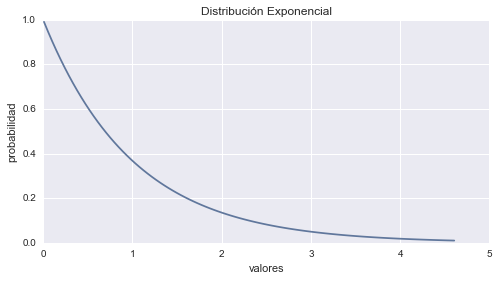
Distribución de Exponencial
La Distribución Exponencial esta dada por la formula:
$$p(x;\alpha) = \frac{1}{ \alpha} e^{\frac{-x}{\alpha}} $$En dónde tanto la variable \(x\) como el parámetro \(\alpha\) son números reales positivos. La Distribución Exponencial tiene bastantes aplicaciones, tales como la desintegración de un átomo radioactivo o el tiempo entre eventos en un proceso de Poisson donde los acontecimientos suceden a una velocidad constante.
# Graficando Exponencial
exponencial = stats.expon()
x = np.linspace(exponencial.ppf(0.01),
exponencial.ppf(0.99), 100)
fp = exponencial.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución Exponencial')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
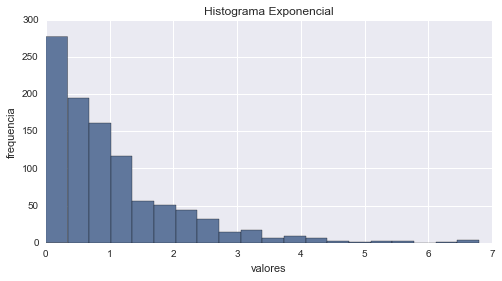
# histograma
aleatorios = exponencial.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Exponencial')
plt.show()
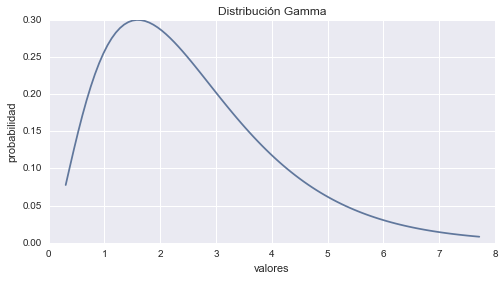
Distribución Gamma
La Distribución Gamma esta dada por la formula:
$$p(x;a, b) = \frac{a(a x)^{b -1} e^{-ax}}{\Gamma(b)} $$En dónde los parámetros \(a\) y \(b\) y la variable \(x\) son números reales positivos y \(\Gamma(b)\) es la función gamma. La Distribución Gamma comienza en el origen de coordenadas y tiene una forma bastante flexible. Otras distribuciones son casos especiales de ella.
# Graficando Gamma
a = 2.6 # parametro de forma.
gamma = stats.gamma(a)
x = np.linspace(gamma.ppf(0.01),
gamma.ppf(0.99), 100)
fp = gamma.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución Gamma')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
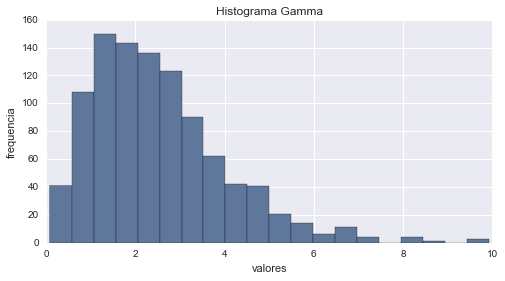
# histograma
aleatorios = gamma.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Gamma')
plt.show()
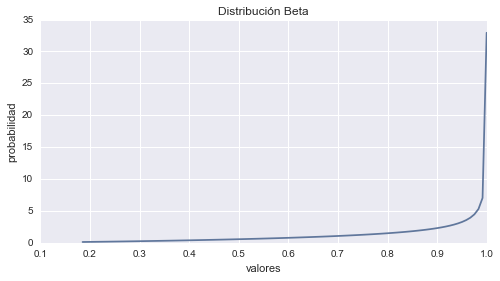
Distribución Beta
La Distribución Beta esta dada por la formula:
$$p(x;p, q) = \frac{1}{B(p, q)} x^{p-1}(1 - x)^{q-1} $$En dónde los parámetros \(p\) y \(q\) son números reales positivos, la variable \(x\) satisface la condición \(0 \le x \le 1\) y \(B(p, q)\) es la función beta. Las aplicaciones de la Distribución Beta incluyen el modelado de variables aleatorias que tienen un rango finito de \(a\) hasta \(b\). Un ejemplo de ello es la distribución de los tiempos de actividad en las redes de proyectos. La Distribución Beta se utiliza también con frecuencia como una probabilidad a priori para proporciones [binomiales]((https://es.wikipedia.org/wiki/Distribuci%C3%B3n_binomial) en el análisis bayesiano.
# Graficando Beta
a, b = 2.3, 0.6 # parametros de forma.
beta = stats.beta(a, b)
x = np.linspace(beta.ppf(0.01),
beta.ppf(0.99), 100)
fp = beta.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución Beta')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
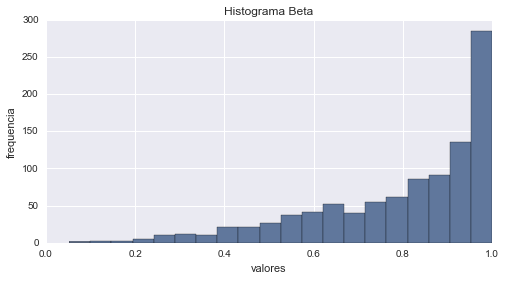
# histograma
aleatorios = beta.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Beta')
plt.show()
Distribución Chi cuadrado
La Distribución Chi cuadrado esta dada por la función:
$$p(x; n) = \frac{\left(\frac{x}{2}\right)^{\frac{n}{2}-1} e^{\frac{-x}{2}}}{2\Gamma \left(\frac{n}{2}\right)} $$En dónde la variable \(x \ge 0\) y el parámetro \(n\), el número de grados de libertad, es un número entero positivo. Una importante aplicación de la Distribución Chi cuadrado es que cuando un conjunto de datos es representado por un modelo teórico, esta distribución puede ser utilizada para controlar cuan bien se ajustan los valores predichos por el modelo, y los datos realmente observados.
# Graficando Chi cuadrado
df = 34 # parametro de forma.
chi2 = stats.chi2(df)
x = np.linspace(chi2.ppf(0.01),
chi2.ppf(0.99), 100)
fp = chi2.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución Chi cuadrado')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = chi2.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma Chi cuadrado')
plt.show()
Distribución T de Student
La Distribución t de Student esta dada por la función:
$$p(t; n) = \frac{\Gamma(\frac{n+1}{2})}{\sqrt{n\pi}\Gamma(\frac{n}{2})} \left( 1 + \frac{t^2}{2} \right)^{-\frac{n+1}{2}} $$En dónde la variable \(t\) es un número real y el parámetro \(n\) es un número entero positivo. La Distribución t de Student es utilizada para probar si la diferencia entre las medias de dos muestras de observaciones es estadísticamente significativa. Por ejemplo, las alturas de una muestra aleatoria de los jugadores de baloncesto podría compararse con las alturas de una muestra aleatoria de jugadores de fútbol; esta distribución nos podría ayudar a determinar si un grupo es significativamente más alto que el otro.
# Graficando t de Student
df = 50 # parametro de forma.
t = stats.t(df)
x = np.linspace(t.ppf(0.01),
t.ppf(0.99), 100)
fp = t.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución t de Student')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = t.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma t de Student')
plt.show()
Distribución de Pareto
La Distribución de Pareto esta dada por la función:
$$p(x; \alpha, k) = \frac{\alpha k^{\alpha}}{x^{\alpha + 1}} $$En dónde la variable \(x \ge k\) y el parámetro \(\alpha > 0\) son números reales. Esta distribución fue introducida por su inventor, Vilfredo Pareto, con el fin de explicar la distribución de los salarios en la sociedad. La Distribución de Pareto se describe a menudo como la base de la regla 80/20. Por ejemplo, el 80% de las quejas de los clientes con respecto al funcionamiento de su vehículo por lo general surgen del 20% de los componentes.
# Graficando Pareto
k = 2.3 # parametro de forma.
pareto = stats.pareto(k)
x = np.linspace(pareto.ppf(0.01),
pareto.ppf(0.99), 100)
fp = pareto.pdf(x) # Función de Probabilidad
plt.plot(x, fp)
plt.title('Distribución de Pareto')
plt.ylabel('probabilidad')
plt.xlabel('valores')
plt.show()
# histograma
aleatorios = pareto.rvs(1000) # genera aleatorios
cuenta, cajas, ignorar = plt.hist(aleatorios, 20)
plt.ylabel('frequencia')
plt.xlabel('valores')
plt.title('Histograma de Pareto')
plt.show()
¿Cómo elegir la distribución que mejor se ajusta a mis datos?
Ahora ya tenemos un conocimiento general de las principales distribuciones con que nos podemos encontrar; pero ¿cómo determinamos que distribución debemos utilizar?
Un modelo que podemos seguir cuando nos encontramos con datos que necesitamos ajustar a una distribución, es comenzar con los datos sin procesar y responder a cuatro preguntas básicas acerca de los mismos, que nos pueden ayudar a caracterizarlos. La primer pregunta se refiere a si los datos pueden tomar valores discretos o continuos. La segunda pregunta que nos debemos hacer, hace referencia a la simetría de los datos y si hay asimetría, en qué dirección se encuentra; en otras palabras, son los valores atípicos positivos y negativos igualmente probables o es uno más probable que el otro. La tercer pregunta abarca los límites superiores e inferiores en los datos; hay algunos datos, como los ingresos, que no pueden ser inferiores a cero, mientras que hay otros, como los márgenes de operación que no puede exceder de un valor (100%). La última pregunta se refiere a la posibilidad de observar valores extremos en la distribución; en algunos casos, los valores extremos ocurren con muy poca frecuencia, mientras que en otros, se producen con mayor frecuencia. Este proceso, lo podemos resumir en el siguiente gráfico:

Con la ayuda de estas preguntas fundamentales, más el conocimiento de las distintas distribuciones deberíamos estar en condiciones de poder caracterizar cualquier conjunto de datos.
Con esto concluyo este tour por las principales distribuciones utilizadas en estadística. Para más información también pueden visitar mi artículo Probabilidad y Estadística con Python o la categoría estadística del blog. Espero les resulte útil.
Saludos!
Este post fue escrito utilizando Jupyter notebook. Pueden descargar este notebook o ver su version estática en nbviewer.