Visualizaciones de datos con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, análisis de datos y python. El contenido esta bajo la licencia BSD.

Introducción
Las visualizaciones son una herramienta fundamental para entender y compartir ideas sobre los datos. La visualización correcta puede ayudar a expresar una idea central, o abrir un espacio para una más profunda investigación; con ella se puede conseguir que todo el mundo hable sobre un conjunto de datos, o compartir una visión sobre lo que los datos nos quieren decir.
Una buena visualización puede dar a quien la observa un sentido rico y amplio de un conjunto de datos. Puede comunicar los datos de manera precisa a la vez que expone los lugares en dónde se necesita más información o dónde una hipótesis no se sostiene. Por otra parte, la visualización nos proporciona un lienzo para aplicar nuestras propias ideas, experiencias y conocimientos cuando observamos y analizamos datos, permitiendo realizar múltiples interpretaciones. Si como dice el dicho “una imagen vale más que mil palabras”, un gráfico interactivo bien elegido entonces podría valer cientos de pruebas estadísticas.
Librerías para visualizar datos en Python
Como bien sabemos, la comunidad de Python es muy grande, por lo tanto vamos a poder encontrar un gran número de librerías para visualizar datos. Al tener tanta variedad de opciones, a veces se hace realmente difícil determinar cuando utilizar cada una de ellas. En este artículo yo voy a presentar solo cuatro que creo que cubren un gran abanico de casos:
-
Matplotlib: Que es la más antigua y se convirtió en la librería por defecto para visualizaciones de datos; muchas otras están basadas en ella. Es extremadamente potente, pero con ese poder viene aparejada la complejidad. Se puede hacer prácticamente de todo con Matplotlib pero no siempre es tan fácil de averiguar como hacerlo. Los que siguen el blog me habrán visto utilizarla en varios artículos.
-
Bokeh: Una de las más jóvenes librerías de visualizaciones, pero no por ello menos potente. Bokeh es una librería para visualizaciones interactivas diseñada para funcionar en los navegadores web modernos. Su objetivo es proporcionar una construcción elegante y concisa de gráficos modernos al estilo de D3.js, y para ampliar esta capacidad con la interactividad y buen rendimiento sobre grandes volúmenes de datos. Bokeh puede ayudar a cualquier persona a crear en forma rápida y sencilla gráficos interactivos, dashboards y aplicaciones de datos. Puede crear tanto gráficos estáticos como gráficos interactivos en el servidor de Bokeh.
-
Seaborn: Si de gráficos estadísticos se trata, Seaborn es la librería que deberíamos utilizar, con ella podemos crear gráficos estadísticos informativos y atractivos de forma muy sencilla. Es una de las tantas librerías que se basan en Matplotlib pero nos ofrece varias características interesantes tales como temas, paletas de colores, funciones y herramientas para visualizar distribuciones de una o varias variables aleatorias, regresiones lineales, series de tiempo, entre muchas otras. Con ella podemos construir visualizaciones complejas en forma sencilla.
-
Folium: Si lo que necesitamos es visualizar datos de geolocalización en mapas interactivos, entonces Folium es una muy buena opción. Esta librería de Python es una herramienta sumamente poderosa para realizar mapas al estilo leaflet.js. El hecho de que los resultados de Folium son interactivos hace que esta librería sea útil para la construcción de dashboards.
¿Cómo elegir la visualización adecuada?
Una de las primeras preguntas que nos debemos realizar al explorar datos es ¿qué método de visualización es más efectivo?. Para intentar responder esta pregunta podemos utilizar la siguiente guía:

Como podemos ver, la guía se divide en cuatro categorías principales y luego se clasifican los distintos métodos de visualización que mejor representan cada una de esas categorías. Veamos un poco más en detalle cada una de ellas:
-
Distribuciones: En esta categoría intentamos comprender como los datos se distribuyen. Se suelen utilizar en el comienzo de la etapa de exploración de datos, cuando queremos comprender las variables. Aquí también nos vamos a encontrar con variables de dos tipos cuantitativas y categóricas. Dependiendo del tipo y cantidad de variables, el método de visualización que vamos a utilizar.
-
Comparaciones: En esta categoría el objetivo es comparar valores a través de diferentes categorías y con el tiempo (tendencia). Los tipos de gráficos más comunes en esta categoría son los diagramas de barras para cuando estamos comparando elementos o categorías y los diagramas de puntos y líneas cuando comparamos variables cuantitativas.
-
Relaciones: Aquí el objetivo es comprender la relación entre dos o más variables. La visualización más utilizada en esta categoría es el gráfico de dispersión.
-
Composiciones: En esta categoría el objetivo es comprender como esta compuesta o distribuida una variable; ya sea a través del tiempo o en forma estática. Las visualizaciones más comunes aquí son los diagramas de barras y los gráficos de tortas.
Ejemplos en Python
Luego de esta introducción es hora de ensuciarse las manos y ponerse a jugar con algunos ejemplos en el uso de cada una de estas 4 librerías que nos ofrece Python para visualización de datos. Obviamente los ejemplos van a ser sencillos ya que un tutorial exhaustivo sobre cada herramienta requeriría mucho más espacio.
Matplotlib
Comencemos con Matplotlib; como les comentaba, es tal vez la librería más utilizada para gráficos en 2d. El objeto pyplot nos proporciona la interfase principal sobre la que podemos crear las visualizaciones de datos con esta librería.
Ver Código
# <!-- collapse=True -->
# importando modulos necesarios
import numpy as np
import pandas as pd
#from pydataset import data
import re
# librerías de visualizaciones
import seaborn as sns
import matplotlib.pyplot as plt
from bokeh.io import output_notebook, show
from bokeh.plotting import Histogram, Scatter
import folium
# graficos incrustados
%matplotlib inline
output_notebook()
# Cargamos algunos datasets de ejemplo
iris = data('iris')
tips = data('tips')
# Ejemplo matplotlib
# graficanco funciones seno y coseno
X = np.linspace(-np.pi, np.pi, 256, endpoint=True)
C, S = np.cos(X), np.sin(X)
# configurando el tamaño de la figura
plt.figure(figsize=(8, 6))
# dibujando las curvas
plt.plot(X, C, color="blue", linewidth=2.5, linestyle="-", label="coseno")
plt.plot(X, S, color="red", linewidth=2.5, linestyle="-", label="seno")
# personalizando los valores de los ejes
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi],
[r'$-\pi$', r'$-\pi/2$', r'$0$', r'$+\pi/2$', r'$+\pi$'])
plt.yticks([-1, 0, +1],
[r'$-1$', r'$0$', r'$+1$'])
# agregando la leyenda
plt.legend(loc='upper left')
# moviendo los ejes de coordenadas
ax = plt.gca() # get current axis
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
# mostrando el resultado
plt.show()
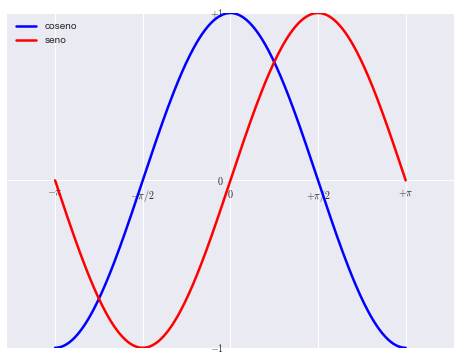
En este primer ejemplo vemos como podemos acceder a la API de Matplotlib desde el objeto pyplot e ir dando forma al gráfico. Veamos ahora unos ejemplos con el dataset iris.
# Ejemplo con iris
# histograma de Petal.Length
iris.head()
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
# separo en especies
setosa = iris[iris.Species == 'setosa']
versicolor = iris[iris.Species == 'versicolor']
virginica = iris[iris.Species == 'virginica']
# crear histograma
plt.figure(figsize=(10, 8))
n, bins, patches = plt.hist(setosa['Petal.Length'], 12,
facecolor='red', label='setosa')
n, bins, patches = plt.hist(versicolor['Petal.Length'], 12,
facecolor='green', label='versicolor')
n, bins, patches = plt.hist(virginica['Petal.Length'], 12,
facecolor='blue', label='virginica')
plt.legend(loc='top_right')
plt.title('Histograma largo del pétalo')
plt.xlabel('largo del pétalo')
plt.ylabel('cuenta largo del pétalo')
plt.show()
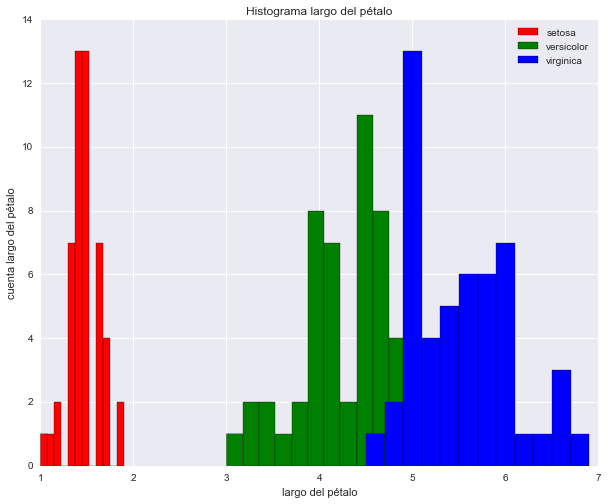
# Ejemplo diagrama de dispersion entre Petal.Length y Petal.Width
plt.figure(figsize=(10, 8))
plt.scatter(setosa['Petal.Length'], setosa['Petal.Width'],
c='red', label='setosa')
plt.scatter(versicolor['Petal.Length'], versicolor['Petal.Width'],
c='green', label='versicolor')
plt.scatter(virginica['Petal.Length'], virginica['Petal.Width'],
c='blue', label='virginica')
plt.title('Tamaño del pétalo')
plt.xlabel('Largo del pétalo (cm)')
plt.ylabel('Ancho del pétalo (cm)')
plt.legend(loc='top_left')
plt.show()
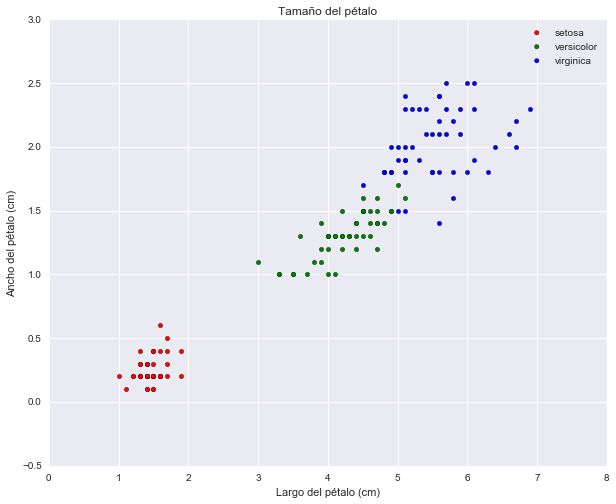
Bokeh
Bokeh además de generar unos hermosos gráficos interactivos nos permite realizar gráficos complejos en forma muy sencilla. La interfase de alto nivel con la que vamos a trabajar principalmente para generar visualizaciones con esta librería es bokeh.charts. Repitamos los ejemplos que realizamos anteriormente sobre el dataset iris y veamos que sencillo que es realizarlos con Bokeh.
# Ejemplo de histograma de Petal.Length
# solo 2 lineas de código
hist = Histogram(iris, values="Petal.Length", color="Species",
legend="top_right", bins=12)
show(hist)
<div class="bk-root">
<div class="plotdiv" id="c195cf80-93de-4663-b5d3-f106a1051aec"></div>
</div>
# Ejemplo diagrama de dispersion entre Petal.Length y Petal.Width
# solo 2 lineas de código
disp = Scatter(iris, x='Petal.Length', y='Petal.Width', color='Species',
legend='top_left', marker='Species', title="Tamaño del petalo")
show(disp)
<div class="bk-root">
<div class="plotdiv" id="ab950219-9790-4c01-8a06-67fa0b5f89e7"></div>
</div>
Seaborn
Seaborn tiene su énfasis en los gráficos estadísticos. Nos permite realizar fácilmente gráficos de regresión y de las principales distribuciones; pero donde realmente brilla Seaborn es en su capacidad de visualizar muchas características diferentes a la vez. Veamos algunos ejemplos
# Ejemplo gráfico de distribuciones
x = np.random.normal(size=100)
dist= sns.distplot(x)
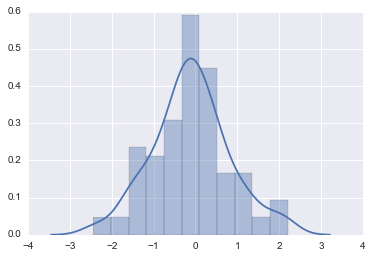
# Ejemplo gráfico regresión con tips dataset
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 1 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 2 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 3 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 4 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 5 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
reg = sns.regplot(x="total_bill", y="tip", data=tips)
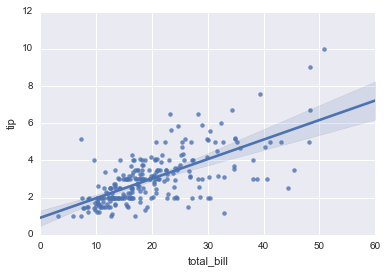
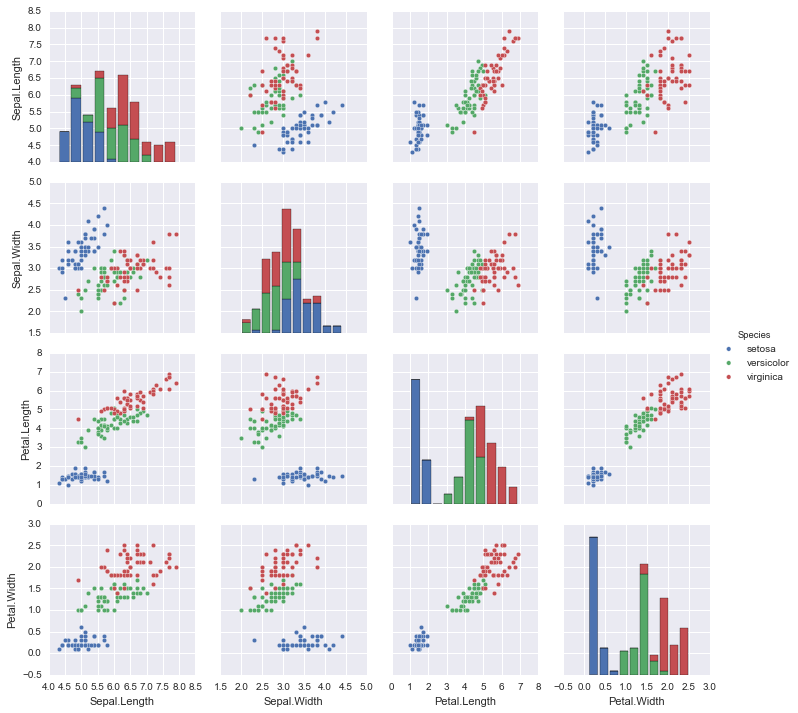
# Ejemplo pairplot con datase iris
g = sns.pairplot(iris, hue="Species", diag_kind="hist")
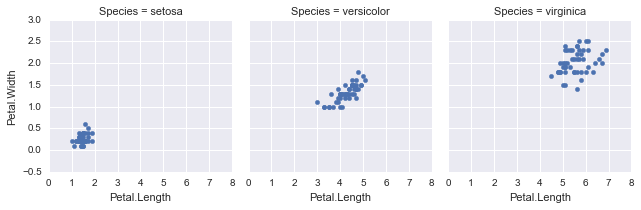
# Ejemplo FacetGrid con iris
g = sns.FacetGrid(iris, col="Species")
g = g.map(plt.scatter, "Petal.Length", "Petal.Width")
Folium
Por último, veamos un ejemplo de como utilizar Folium. Ya que yo soy adepto al uso de la bicicleta para moverme por la ciudad, y muchas veces se hace difícil encontrar una bicicletería en donde poder encontrar repuestos o reparar la bicicleta; en este ejemplo vamos a crear un mapa interactivo del barrio de Palermo en donde vamos a marcar la ubicación de los negocios de bicicleterías. Esta información la podemos extraer del padrón que ofrece el gobierno de la Ciudad de Buenos Aires en su portal de datos.
# dataset de bicicleterías de Ciudad de Buenos Aires
# descargado desde https://data.buenosaires.gob.ar/dataset/bicicleterias
bici = pd.read_csv('data/bicicleterias.csv', sep=';')
bici.head()
| WKT | ID | NOMBRE | DIRECCION | TELEFONO | WEB | ||
|---|---|---|---|---|---|---|---|
| 0 | POINT (-58.466041249451614 -34.557060215984805) | 52 | 11 A FONDO | CONGRESO 2757 | 45421835 | info@11afondo.com | https://WWW.11AFONDO.COM |
| 1 | POINT (-58.41279876038783 -34.591915372813645) | 32 | AMERICAN BIKE | AV. CNEL. DIAZ 1664 | 48220889 | info@americanbike.com.ar | https://WWW.AMERICANBIKE.COM.AR/ |
| 2 | POINT (-58.425646989945932 -34.580365554062418) | 30 | ANDINO BIKES | GUEMES 4818 | 47753677 | andino_bike@hotmail.com | https://WWW.ANDINOBIKE.COM.AR/ |
| 3 | POINT (-58.437608880680997 -34.6045094278806) | 107 | BABE BIKES | WARNES 10 | 48549862 | info@babebikes.com.ar | |
| 4 | POINT (-58.439598908303168 -34.58547499220991) | 118 | BELGRAVIA TAILOR MADE BICYLES | BONPLAND 1459 | 1544291001 | hola@belgravia.com.ar | WWW.FACEBOOK.COM/BELGRAVIABIKES |
# corregimos el campo de coordenadas del dataset.
def coord(c):
coor = re.findall(r'-?\d+\.\d{7}', c)
coords = [float(s) for s in coor]
return coords[::-1]
bici['WKT'] = bici['WKT'].apply(coord)
# filtramos solo las bicicleterías de palermo
bici_palermo = bici[bici.BARRIO == 'PALERMO'][['WKT', 'NOMBRE']]
# creamos el mapa con folium
mapa = folium.Map(location=[-34.588889, -58.430556], zoom_start=13)
# agregamos los markers con el nombre de cada bicicletería.
for index, row in bici_palermo.iterrows():
mapa.simple_marker(row['WKT'],
popup=row['NOMBRE'], marker_color='red',
marker_icon='info-sign')
# visualizamos el mapa con los markers
mapa
Aquí concluye este artículo, ya no hay excusas para graficar sus datos, como vimos Python cuenta con herramientas que son fáciles de usar y muy poderosas. A divertirse!
Saludos!
Este post fue escrito utilizando IPython notebook. Pueden descargar este notebook o ver su version estática en nbviewer.