Introducción a la teoría de probabilidad con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, análisis de datos y python. El contenido esta bajo la licencia BSD.

“En el fondo, la teoría de probabilidades es sólo sentido común expresado con números”
Introducción: probabilidad y sentido común
La incertidumbre constituye una pieza fundamental del mundo en que vivimos, en parte hace la vida mucho más interesante, ya que sería muy aburrido si todo fuera perfectamente predecible. Aun así, una parte de nosotros quisiera predecir el futuro y que las cosas sean mucho más predecibles. Para poder lidiar con la incertidumbre que nos rodea, solemos aplicar lo que llamamos nuestro “sentido común”. Por ejemplo, si al levantarnos por la mañana vemos que el día se encuentra nublado, este hecho no nos da la certeza de que comenzará a llover más tarde; sin embargo, nuestro sentido común puede inducirnos a cambiar nuestros planes y a actuar como si creyéramos que fuera a llover si las nubes son los suficientemente oscuras o si escuchamos truenos, ya que nuestra experiencia nos dice que estos signos indicarían una mayor posibilidad de que el hecho de que fuera a llover más tarde realmente ocurra. Nuestro sentido común es algo tan arraigado en nuestro pensamiento, que lo utilizamos automáticamente sin siquiera ponernos a pensar en ello; pero muchas veces, el sentido común también nos puede jugar una mala pasada y hacernos elegir una respuesta incorrecta.
Tomemos por ejemplo alguna de las siguiente situaciones…
-
Situación 1 - La coincidencia de cumpleaños: Vamos a una fiesta a la que concurren un total de 50 personas. Allí un amigo nos desafía afirmando que en la fiesta debe haber por lo menos 2 personas que cumplen años el mismo día y nos apuesta 100 pesos a que está en lo correcto. Es decir, que si él acierta deberíamos pagarle los 100 pesos; o en caso contrario, el nos pagará los 100 pesos. ¿Deberíamos aceptar la apuesta?
-
Situación 2 - ¿Que puerta elegir?: Estamos participando en un concurso en el cual se nos ofrece la posibilidad de elegir una entre tres puertas. Tras una de ellas se encuentra una ferrari ultimo modelo, y detrás de las otras dos hay una cabra; luego de elegir una puerta, el presentador del concurso abre una de las puertas restantes y muestra que hay una cabra (el presentador sabe que hay detrás de cada puerta). Luego de hacer esto, el presentador nos ofrece la posibilidad de cambiar nuestra elección inicial y quedarnos con la otra puerta que no habíamos elegido inicialmente. ¿Deberíamos cambiar o confiar en nuestra elección inicial?
¿Qué les diría su sentido común que deberían hacer en cada una de estas situaciones?
Para poder responder éstas y otras preguntas de una manera más rigurosa, primero deberíamos de alguna forma modelar matemáticamente nuestro sentido común, es aquí, como lo expresa la frase del comienzo del artículo, como surge la teoría de probabilidad.
¿Qué es la teoría de probabilidad?
La teoría de probabilidad es la rama de las matemáticas que se ocupa de los fenómenos aleatorios y de la incertidumbre. Existen muchos eventos que no se pueden predecir con certeza; ya que su observación repetida bajo un mismo conjunto específico de condiciones puede arrojar resultados distintos, mostrando un comportamiento errático e impredecible. En estas situaciones, la teoría de probabilidad proporciona los métodos para cuantificar las posibilidades, o probabilidades, asociadas con los diversos resultados. Su estudio ha atraído a un gran número de gente, ya sea por su interés intrínseco como por su aplicación con éxito en las ciencias físicas, biológicas y sociales, así como también en áreas de la ingeniería y en el mundo de los negocios.
Cuantificando la incertidumbre
Ahora bien, en la definición de arriba dijimos que la teoría de probabilidad, nos proporciona las herramientas para poder cuantificar la incertidumbre, pero ¿cómo podemos realmente cuantificar estos eventos aleatorios y hacer inferencias sobre ellos? La respuesta a esta pregunta es, a su vez, intuitiva y simple; la podemos encontrar en el concepto del espacio de muestreo.
El Espacio de muestreo
El espacio de muestreo hace referencia a la idea de que los posibles resultados de un proceso aleatorio pueden ser pensados como puntos en el espacio. En los casos más simples, este espacio puede consistir en sólo algunos puntos, pero en casos más complejos puede estar representado por un continuo, como el espacio en que vivimos. El espacio de muestreo , en general se expresa con la letra \(S\), y consiste en el conjunto de todos los resultados posibles de un experimento. Si el experimento consiste en el lanzamiento de una moneda, entonces el espacio de muestreo será \(S = {cara, seca }\), ya que estas dos alternativas representan a todos los resultados posibles del experimento. En definitiva el espacio de muestreo no es más que una simple enumeración de todos los resultados posibles, aunque las cosas nunca suelen ser tan simples como aparentan. Si en lugar de considerar el lanzamiento de una moneda, lanzamos dos monedas; uno podría pensar que el espacio de muestreo para este caso será \(S = {\text{ 2 caras}, \text{2 secas}, \text{cara y seca} }\); es decir que de acuerdo con este espacio de muestreo la probabilidad de que obtengamos dos caras es 1 en 3; pero la verdadera probabilidad de obtener dos caras, confirmada por la experimentación, es 1 en 4; la cual se hace evidente si definimos correctamente el espacio de muestreo, que será el siguiente: \(S = {\text{ 2 caras}, \text{2 secas}, \text{cara y seca}, \text{seca y cara} }\). Como este simple ejemplo nos enseña, debemos ser muy cuidadosos al definir el espacio de muestreo, ya que una mala definición del mismo, puede inducir a cálculos totalmente errados de la probabilidad.
Independencia, la ley de grandes números y el teorema del límite central
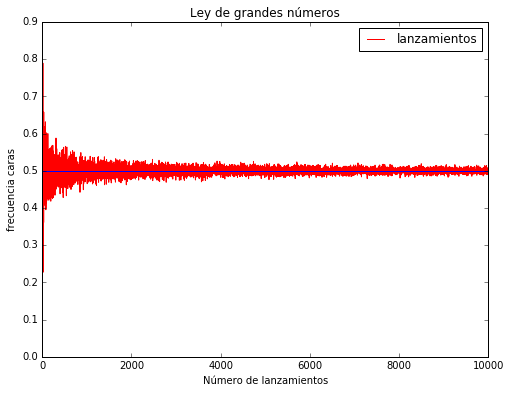
Una de las cosas más fascinantes sobre el estudio de la teoría de probabilidad es que si bien el comportamiento de un evento individual es totalmente impredecible, el comportamiento de una cantidad suficientemente grande de eventos se puede predecir con un alto grado de certeza!. Si tomamos el caso clásico del lanzamiento de una moneda, no podemos predecir con exactitud cuantas caras podemos obtener luego de 10 tiradas, tal vez el azar haga que obtengamos 7, 10, o 3 caras, dependiendo de con cuanta suerte nos encontremos; pero si repetimos el lanzamiento un millón de veces, casi con seguridad que la cantidad de caras se aproximará a la verdadera probabilidad subyacente del experimento, es decir, al 50% de los lanzamientos. Este comportamiento es lo que en la teoría de probabilidad se conoce con el nombre de ley de grandes números; pero antes de poder definir esta ley, primero debemos describir otro concepto también muy importante, la independencia de los eventos .
El concepto de independencia
En teoría de probabilidad, podemos decir que dos eventos son independientes cuando la probabilidad de cada uno de ellos no se ve afecta porque el otro evento ocurra, es decir que no existe ninguna relación entre los eventos. En el lanzamiento de la moneda; la moneda no sabe, ni le interesa saber si el resultado del lanzamiento anterior fue cara; cada lanzamiento es un suceso totalmente aislado el uno del otro y la probabilidad del resultado va a ser siempre 50% en cada lanzamiento.
Definiendo la ley de grandes números
Ahora que ya conocemos el concepto de independencia, estamos en condiciones de dar una definición más formal de la ley de grandes números, que junto con el Teorema del límite central, constituyen los cimientos de la teoría de probabilidad. Podemos formular esta ley de la siguiente manera: si se repite un experimento aleatorio, bajo las mismas condiciones, un número ilimitado de veces; y si estas repeticiones son independientes la una de la otra, entonces la frecuencia de veces que un evento \(A\) ocurra, convergerá con probabilidad 1 a un número que es igual a la probabilidad de que \(A\) ocurra en una sola repetición del experimento. Lo que esta ley nos enseña, es que la probabilidad subyacente de cualquier suceso aleatorio puede ser aprendido por medio de la experimentación, simplemente tendríamos que repetirlo una cantidad suficientemente grande de veces!. Un error que la gente suele cometer y asociar a esta ley, es la idea de que un evento tiene más posibilidades de ocurrir porque ha o no ha ocurrido recientemente. Esta idea de que las chances de un evento con una probabilidad fija, aumentan o disminuyen dependiendo de las ocurrencias recientes del evento, es un error que se conoce bajo el nombre de la falacia del apostador.
Para entender mejor la ley de grandes números, experimentemos con algunos ejemplos en Python. Utilicemos nuevamente el ejemplo del lanzamiento de la moneda, en el primer ejemplo, la moneda va a tener la misma posibilidad de caer en cara o seca; mientras que en el segundo ejemplo, vamos a modificar la probabilidad de la moneda para que caiga cara solo en 1 de 6 veces.
Ver Código
# <!-- collapse=True -->
# importando modulos necesarios
import matplotlib.pyplot as plt
import numpy as np # importando numpy
import pandas as pd # importando pandas
np.random.seed(2131982) # para poder replicar el random
%matplotlib inline
# Ejemplo ley de grandes números
# moneda p=1/2 cara=1 seca=0
resultados = []
for lanzamientos in range(1,10000):
lanzamientos = np.random.choice([0,1], lanzamientos)
caras = lanzamientos.mean()
resultados.append(caras)
# graficamente
df = pd.DataFrame({ 'lanzamientos' : resultados})
df.plot(title='Ley de grandes números',color='r',figsize=(8, 6))
plt.axhline(0.5)
plt.xlabel("Número de lanzamientos")
plt.ylabel("frecuencia caras")
plt.show()
# moneda p=1/6 cara=1 seca=0
resultados = []
for lanzamientos in range(1,10000):
lanzamientos = np.random.choice([0,1], lanzamientos, p=[5/6, 1/6])
caras = lanzamientos.mean()
resultados.append(caras)
# graficamente
df = pd.DataFrame({ 'lanzamientos' : resultados})
df.plot(title='Ley de grandes números',color='r',figsize=(8, 6))
plt.axhline(1/6)
plt.xlabel("Número de lanzamientos")
plt.ylabel("frecuencia caras")
plt.show()
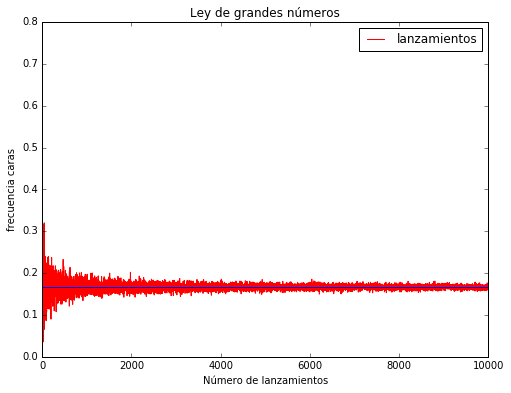
Como estos ejemplos nos muestran, al comienzo, la frecuencia en que vamos obteniendo caras va variando considerablemente, pero a medida que aumentamos el número de repeticiones, la frecuencia de caras se va estabilizando en la probabilidad subyacente el evento, 1 en 2 para el primer caso y 1 en 6 para el segundo ejemplo. En los gráficos podemos ver claramente el comportamiento de la ley.
El Teorema del límite central
El otro gran teorema de la teoría de probabilidad es el Teorema del límite central. Este teorema establece que la suma o el promedio de casi cualquier conjunto de variables independientes generadas al azar se aproximan a la Distribución Normal. El Teorema del límite central explica por qué la Distribución Normal surge tan comúnmente y por qué es generalmente una aproximación excelente para la media de casi cualquier colección de datos. Este notable hallazgo se mantiene verdadero sin importar la forma que adopte la distribución de datos que tomemos. Para ilustrar también este teorema, recurramos a un poco más de Python.
# Ejemplo teorema del límite central
muestra_binomial = []
muestra_exp = []
muestra_possion = []
muestra_geometric = []
mu = .9
lam = 1.0
size=1000
for i in range(1,20000):
muestra = np.random.binomial(1, mu, size=size)
muestra_binomial.append(muestra.mean())
muestra = np.random.exponential(scale=2.0,size=size)
muestra_exp.append(muestra.mean())
muestra = np.random.geometric(p=.5, size=size)
muestra_geometric.append(muestra.mean())
muestra = np.random.poisson (lam=lam, size=size)
muestra_possion.append(muestra.mean())
df = pd.DataFrame({ 'binomial' : muestra_binomial,
'poission' : muestra_possion,
'geometrica' : muestra_geometric,
'exponencial' : muestra_exp})
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10,10))
df.binomial.hist(ax=axes[0,0], alpha=0.9, bins=1000)
df.exponencial.hist(ax=axes[0,1],bins=1000)
df.poission.hist(ax=axes[1,0],bins=1000)
df.geometrica.hist(ax=axes[1,1],bins=1000)
axes[0,0].set_title('Binomial')
axes[0,1].set_title('Poisson')
axes[1,0].set_title('Geométrica')
axes[1,1].set_title('Exponencial')
plt.show()
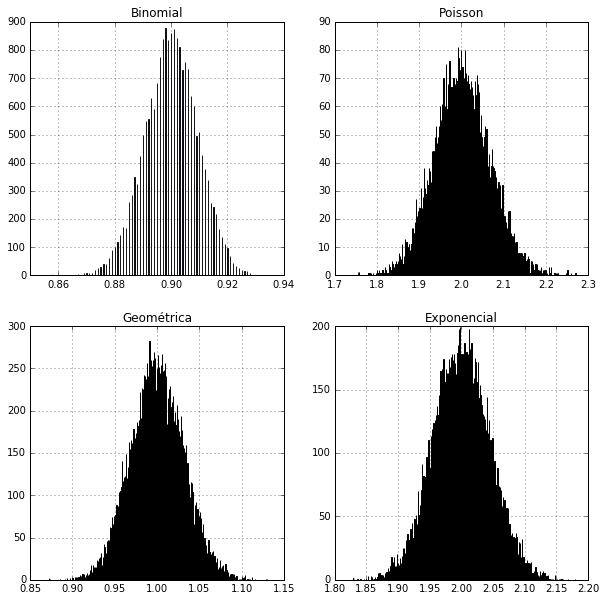
Como nos muestra este ejemplo, al graficar la distribución de las medias de las distribuciones Binomial, Poisson, Geométrica y Exponencial; vemos que todas ellas responden a la famosa forma de campana de la Distribución Normal!. Algo realmente sorprendente!
Calculando probabilidades
Saber calcular la probabilidad de que un evento o varios eventos ocurran puede ser una habilidad valiosa al tomar decisiones, ya sea en la vida real o jugando juegos de azar. Cómo calcular la probabilidad, sin embargo, cambia dependiendo del tipo de evento que se está observando. Por ejemplo, no calcularíamos nuestras posibilidades de ganar la lotería de la misma manera que calcularíamos nuestras posibilidades de obtener una generala servida en un juego de dados. Sin embargo, una vez que determinamos si los eventos son independientes, condicionales o mutuamente excluyentes, calcular su probabilidad es relativamente simple.
Propiedades básicas de la probabilidad
Antes de poder calcular las probabilidades, primero debemos conocer sus 3 propiedades fundamentales, ellas son:
- La probabilidad se expresa como un ratio que será un valor positivo menor o igual a 1.
\( 0 \le p(A) \le 1\)
- La probabilidad de un evento del que tenemos total certeza es 1.
\() p(S) = 1 \)
- Si el evento \(A\) y el evento \(B\) son mutuamente excluyentes, entonces:
\( p(A \cup B ) = p(A) + p(B) \)
A partir de estas propiedades básicas, se pueden derivar muchas otras propiedades.
Teoría de conjuntos y probabilidades
En mi artículo sobre conjuntos comentaba que la teoría de conjuntos se ha convertido en un pilar fundamental de las matemáticas, casi cualquier rama de las matemáticas puede ser definida utilizando conjuntos; y la teoría de probabilidad no es la excepción. Antes de poder calcular probabilidades, primero debemos discutir como se relacionan los eventos en términos de la teoría de conjuntos. Las relaciones que podemos encontrar son:
-
Unión: La unión de varios eventos simples crea un evento compuesto que ocurre si uno o más de los eventos ocurren. La unión de \(E\) y \(F\) se escribe \(E \cup F\) y significa “Ya sea \(E\) o \(F\), o ambos \(E\) y \(F\).”
-
Intersección: La intersección de dos o más eventos simples crea un evento compuesto que ocurre sólo si ocurren todos los eventos simples. La intersección de \(E\) y \(F\) se escribe \(E \cap F\) y significa “\(E\) y \(F\).”
-
Complemento: El complemento de un evento significa todo en el espacio de muestreo que no es ese evento. El complemento del evento \(E\) se escribe varias veces como \(\sim{E}\), \(E^c\), o \(\overline{E}\), y se lee como “no \(E\)” o “complemento \(E\)”.
-
Exclusión mutua: Si los eventos no pueden ocurrir juntos, son mutuamente excluyentes. Siguiendo la misma línea de razonamiento, si dos conjuntos no tienen ningún evento en común, son mutuamente excluyentes.
Calculando la probabilidad de múltiples eventos
Ahora sí, ya podemos calcular las probabilidades de los eventos. Recordemos que la probabilidad de un solo evento se expresa como un ratio entre el número de resultados favorables sobre el número de los posibles resultados. Pero ¿qué pasa cuando tenemos múltiples eventos?
Unión de eventos mutuamente excluyentes
Si los eventos son mutuamente excluyentes entonces para calcular la probabilidad de su unión, simplemente sumamos sus probabilidades individuales.
$$p(E \cup F) = p(E) + p(F)$$Unión de eventos que no son mutuamente excluyentes
Si los eventos no son mutuamente excluyentes entonces debemos corregir la fórmula anterior para incluir el efecto de la superposición de los eventos. Esta superposición se da en el lugar de la intersección de los eventos; por lo tanto la formula para calcular la probabilidad de estos eventos es:
$$p(E \cup F) = p(E) + p(F) - p(E \cap F)$$Intersección de eventos independientes
Para calcular la probabilidad de que ocurran varios eventos (la intersección de varios eventos), se multiplican sus probabilidades individuales. La fórmula específica utilizada dependerá de si los eventos son independientes o no. Si son independientes, la probabilidad de \(E\) y \(F\) se calcula como:
$$p(E \cap F) = p(E) \times p(F)$$Intersección de eventos no independientes
Si dos eventos no son independientes, debemos conocer su probabilidad condicional para poder calcular la probabilidad de que ambos se produzcan. La fórmula en este caso es:
$$p(E \cap F) = p(E) \times p(F|E)$$La probabilidad condicional
Con frecuencia queremos conocer la probabilidad de algún evento, dado que otro evento ha ocurrido. Esto se expresa simbólicamente como \(p(E | F)\) y se lee como “la probabilidad de \(E\) dado \(F\)”. El segundo evento se conoce como la condición y el proceso se refiere a veces como “condicionamiento en F”. La probabilidad condicional es un concepto importante de estadística, porque a menudo estamos tratando de establecer que un factor tiene una relación con un resultado, como por ejemplo, que las personas que fuman cigarrillos tienen más probabilidades de desarrollar cáncer de pulmón. La probabilidad condicional también se puede usar para definir la independencia. Dos variables se dice que son independientes si la siguiente relación se cumple:
$$p(E | F) = p(E)$$Calculando la probabilidad condicional
Para calcular la probabilidad del evento \(E\) dada la información de que el evento \(F\) ha ocurrido utilizamos la siguiente formula:
$$p(E | F) = \frac{p(E \cap F)}{p(F)}$$Jugando con Probabilidades y Python
Bien, ahora que ya sabemos como calcular probabilidades, llegó finalmente el momento de ponerse a resolver las situaciones planteadas en el comienzo, para eso vamos a utilizar nuevamente un poco de Python.
Resolviendo la situación 1 - La coincidencia de cumpleaños
La paradoja del cumpleaños es un problema muy conocido en el campo de la teoría de probabilidad. Plantea las siguientes interesantes preguntas: ¿Cuál es la probabilidad de que, en un grupo de personas elegidas al azar, al menos dos de ellas habrán nacido el mismo día del año? ¿Cuántas personas son necesarias para asegurar una probabilidad mayor al 50%?. Excluyendo el 29 de febrero de nuestros cálculos y asumiendo que los restantes 365 días de posibles cumpleaños son igualmente probables, nos sorprendería darnos cuenta de que, en un grupo de sólo 23 personas, la probabilidad de que dos personas compartan la misma fecha de cumpleaños es mayor al 50%!.
Esto ya nos dice algo respecto a nuestras chances en la apuesta con nuestro amigo, pero de todas formas calculemos la probabilidad en un grupo de 50 personas. Calcular la probabilidad de un cumpleaños duplicado puede parecer una tarea desalentadora. Pero ¿qué pasa con calcular la probabilidad de que no haya un cumpleaños duplicado? Esto es realmente una tarea más fácil. Especialmente si simplificamos el problema a un grupo muy pequeño. Supongamos que el grupo sólo tiene una persona, en ese caso, hay una probabilidad del 100% que esta persona no comparte un cumpleaños puesto que no hay nadie más quien compartir. Pero ahora podemos añadir una segunda persona al grupo. ¿Cuáles son las posibilidades de que tenga un cumpleaños diferente de esa persona? De hecho esto es bastante fácil, hay 364 otros días en el año, así que las posibilidades son 364/365. ¿Qué tal si agregamos una tercera persona al grupo? Ahora hay 363/365 días. Para obtener la probabilidad general de que no hay cumpleaños compartidos simplemente multiplicamos las probabilidades individuales. Si utilizamos este procedimiento, con la ayuda de Python podemos calcular fácilmente las probabilidades de un cumpleaños compartido en un grupo de 50 personas.
# Ejemplo situación 2 La coincidencia de cumpleaños
prob = 1.0
asistentes = 50
for i in range(asistentes):
prob = prob * (365-i)/365
print("Probabilidad de que compartan una misma fecha de cumpleaños es {0:.2f}"
.format(1 - prob))
Probabilidad de que compartan una misma fecha de cumpleaños es 0.97
Como vemos, la apuesta de nuestro amigo es casi una apuesta segura para él. Se ve que conoce bastante bien la teoría de probabilidad y quiere disfrutar de la fiesta a consta nuestra!
Resolviendo la situación 2 - ¿Que puerta elegir?
Este problema, más conocido con el nombre de Monty Hall, también es un problema muy popular dentro de la teoría de probabilidad; y se destaca por su solución que a simple vista parece totalmente anti-intuitiva. Intuitivamente, es bastante sencillo que nuestra elección original (cuando hay tres puertas para elegir) tiene una probabilidad de 1/3 de ganar el concurso. Las cosas sin embargo se complican, cuando se descarta una puerta. Muchos dirían que ahora tenemos una probabilidad de 1/2 de ganar, seleccionando cualquiera de las dos puertas; pero este no es el caso. Un aspecto crítico del problema es darse cuenta de que la elección de la puerta a descartar por el presentador, no es una decisión al azar. El presentador puede descartar una puerta porque él sabe (a) qué puerta hemos seleccionado y (b) qué puerta tiene la ferrari. De hecho, en muchos casos, el presentador debe quitar una puerta específica. Por ejemplo, si seleccionamos la puerta 1 y el premio está detrás de la puerta 3, el presentador no tiene otra opción que retirar la puerta 2. Es decir, que la elección de la puerta a descartar está condicionada tanto por la puerta con el premio como por la puerta que seleccionamos inicialmente. Este hecho, cambia totalmente la naturaleza del juego, y hace que las probabilidades de ganar sean 2/3 si cambiamos de puerta!.
Si aun no están convencidos, simulemos los resultados del concurso con la ayuda de Python.
Ver Código
# <!-- collapse=True -->
# Ejemplo situación 2 ¿Que puerta elegir? (el problema Monty Hall)
def elegir_puerta():
"""
Función para elegir una puerta. Devuelve 1, 2, o 3 en forma aleatoria.
"""
return np.random.randint(1,4)
class MontyHall:
"""
Clase para modelar el problema de Monty Hall.
"""
def __init__(self):
"""
Crea la instancia del problema.
"""
# Elige una puerta en forma aleatoria.
self.puerta_ganadora = elegir_puerta()
# variables para la puerta elegida y la puerta descartada
self.puerta_elegida = None
self.puerta_descartada = None
def selecciona_puerta(self):
"""
Selecciona la puerta del concursante en forma aleatoria.
"""
self.puerta_elegida = elegir_puerta()
def descarta_puerta(self):
"""
Con este método el presentador descarta una de la puertas.
"""
# elegir puerta en forma aleatoria .
d = elegir_puerta()
# Si es al puerta ganadora o la del concursante, volver a elegir.
while d == self.puerta_ganadora or d == self.puerta_elegida:
d = elegir_puerta()
# Asignar el valor a puerta_descartada.
self.puerta_descartada = d
def cambiar_puerta(self):
"""
Cambia la puerta del concursante una vez que se elimino una puerta.
"""
# 1+2+3=6. Solo existe una puerta para elegir.
self.puerta_elegida = 6 - self.puerta_elegida - self.puerta_descartada
def gana_concursante(self):
"""
Determina si el concursante gana.
Devuelve True si gana, False si pierde.
"""
return self.puerta_elegida == self.puerta_ganadora
def jugar(self, cambiar=True):
"""
Una vez que la clase se inicio, jugar el concurso.
'cambiar' determina si el concursante cambia su elección.
"""
# El concursante elige una puerta.
self.selecciona_puerta()
# El presentador elimina una puerta.
self.descarta_puerta()
# El concursante cambia su elección.
if cambiar:
self.cambiar_puerta()
# Determinar si el concursante ha ganado.
return self.gana_concursante()
# Ahora, jugamos el concurso. primero nos vamos a quedar con nuestra elección
# inicial. Vamos a ejecutar el experimiento 10.000 veces.
gana, pierde = 0, 0
for i in range(10000):
# Crear la instancia del problema.
s2 = MontyHall()
# ejecutar el concurso sin cambiar de puerta..
if s2.jugar(cambiar=False):
# si devuelve True significa que gana.
gana += 1
else:
# si devuelve False significa que pierde.
pierde += 1
# veamos la fecuencia de victorias del concursante.
porc_gana = 100.0 * gana / (gana + pierde)
print("\n10.000 concursos sin cambiar de puerta:")
print(" gana: {0:} concursos".format(gana))
print(" pierde: {0:} concursos".format(pierde))
print(" probabilidad: {0:.2f} procentaje de victorias".format(porc_gana))
10.000 concursos sin cambiar de puerta:
gana: 3311 concursos
pierde: 6689 concursos
probabilidad: 33.11 procentaje de victorias
# Ahora, jugamos el concurso siempre cambiando la elección inicial
# Vamos a ejecutar el experimiento 10.000 veces.
gana, pierde = 0, 0
for i in range(10000):
# Crear la instancia del problema.
s2 = MontyHall()
# ejecutar el concurso sin cambiar de puerta..
if s2.jugar(cambiar=True):
# si devuelve True significa que gana.
gana += 1
else:
# si devuelve False significa que pierde.
pierde += 1
# veamos la fecuencia de victorias del concursante.
porc_gana = 100.0 * gana / (gana + pierde)
print("\n10.000 concursos cambiando de puerta:")
print(" gana: {0:} concursos".format(gana))
print(" pierde: {0:} concursos".format(pierde))
print(" probabilidad: {0:.2f} procentaje de victorias".format(porc_gana))
10.000 concursos cambiando de puerta:
gana: 6591 concursos
pierde: 3409 concursos
probabilidad: 65.91 procentaje de victorias
Como esta simulación lo demuestra, si utilizamos la estrategia de siempre cambiar de puerta, podemos ganar el concurso un 66% de las veces; mientras que si nos quedamos con nuestra elección inicial, solo ganaríamos el 33% de las veces.
Distintas interpretaciones de la probabilidad
Las probabilidades pueden ser interpretadas generalmente de dos maneras distintas. La interpretación frecuentista u objetivista de la probabilidad es una perspectiva en la que las probabilidades se consideran frecuencias relativas constantes a largo plazo. Este es el enfoque clásico de la teoría de probabilidad. La interpretación Bayesiana o subjetivista de la probabilidad es una perspectiva en la que las probabilidades son consideradas como medidas de creencia que pueden cambiar con el tiempo para reflejar nueva información. El enfoque clásico sostiene que los métodos bayesianos sufren de falta de objetividad, ya que diferentes individuos son libres de asignar diferentes probabilidades al mismo evento según sus propias opiniones personales. Los bayesianos se oponen a los clásicos sosteniendo que la interpretación frecuentista de la probabilidad tiene ya de por sí una subjetividad incorporada (por ejemplo, mediante la elección y el diseño del procedimiento de muestreo utilizado) y que la ventaja del enfoque bayesiano es que ya hace explícita esta subjetividad. En la actualidad, la mayoría de los problemas son abordados siguiendo un enfoque mixto entre ambas interpretaciones de la probabilidad.
El poder de los números aleatorios
Uno podría pensar que un comportamiento aleatorio es caótico y totalmente opuesto a la razón, que sería una forma de renunciar a un problema, un último recurso. Pero lejos de esto, el sorprendente y cada vez más importante rol que viene desempeñando lo aleatorio en las ciencias de la computación nos enseña que el hacer un uso deliberado de lo aleatorio puede ser una forma muy efectiva de abordar los problemas más difíciles; incluso en algunos casos, puede ser el único camino viable. Los Algoritmos probabilísticos como el método Miller-Rabin para encontrar números primos y el método de Monte Carlo, nos demuestran lo poderoso que puede ser utilizar la aleatoriedad para resolver problemas. Muchas veces, la mejor solución a un problema, puede ser simplemente dejarlo al azar en lugar de tratar de razonar totalmente su solución!
Aquí concluye este artículo. Espero les haya resultado útil y encuentren tan fascinante como yo a la teoría de probabilidad; después de todo, la incertidumbre esta en todo lo que nos rodea y la casualidad es un concepto más fundamental que la causalidad!
Saludos!
Este post fue escrito utilizando IPython notebook. Pueden descargar este notebook o ver su version estática en nbviewer.