Introducción a los métodos de Monte-Carlo con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, análisis de datos y python. El contenido esta bajo la licencia BSD.

Introducción
En el cierre de mi artículo anterior, comentaba sobre la sorprendente influencia que han tenido los números aleatorios, que junto con el poder de cálculo que nos proporcionan las computadoras modernas; nos han ayudado a resolver muchos de los problemas numéricos más complejos en ciencia, ingeniería, finanzas y estadísticas. En esencia, detrás de cada una de esas soluciones encontramos una familia de métodos que se conocen bajo el nombre de Métodos de Monte-Carlo.
¿Qué son los métodos de Monte-Carlo?
Los Métodos de Monte-Carlo son técnicas para analizar fenómenos por medio de algoritmos computacionales, que utilizan y dependen fundamentalmente de la generación de números aleatorios. El término Monte-Carlo, hace referencia al casino de Montecarlo, una de las capitales de los juegos de azar; y se utilizó como denominación para estás técnicas por la aleatoriedad inherente que poseen. El estudio de los Métodos de Monte-Carlo requiere un conocimiento detallado en una amplia gama de campos; por ejemplo, la probabilidad para describir los experimentos y procesos aleatorios, la estadística para analizar los datos, las ciencias de la computación para implementar eficientemente los algoritmos y la programación matemática para formular y resolver problemas de optimización.
Como los Métodos de Monte-Carlo dependen en gran medida de la posibilidad de producir, con una computadora, un flujo infinito de variables aleatorias para todo tipo de distribuciones; no podemos hablar de los Métodos de Monte-Carlo, sin antes explicar los números aleatorios y como podemos generarlos con la ayuda de una computadora.
Números aleatorios y Monte-Carlo
En el corazón de los Métodos de Monte-Carlo encontramos un generador de números aleatorios, es decir un procedimiento que produce un flujo infinito de variables aleatorias, que generalmente se encuentran en el intervalo (0, 1); los cuales son independientes y están uniformemente distribuidos de acuerdo a una distribución de probabilidad. La mayoría de los lenguajes de programación hoy en día contienen un generador de números aleatorios por defecto al cual simplemente debemos ingresarle un valor inicial, generalmente llamado seed o semilla, y que luego en cada invocación nos va a devolver un secuencia uniforme de variables aleatorias independientes en el intervalo (0, 1).
Números pseudoaleatorios
El concepto de una secuencia infinita de variables aleatorias es una abstracción matemática que puede ser imposible de implementar en una computadora. En la práctica, lo mejor que se puede hacer es producir una secuencia de números pseudoaleatorios con propiedades estadísticas que son indistinguibles de las de una verdadera secuencia de variables aleatorias. Aunque actualmente métodos de generación física basados en la radiación de fondo o la mecánica cuántica parecen ofrecer una fuente estable de números verdaderamente aleatorios , la gran mayoría de los generadores de números aleatorios que se utilizan hoy en día están basados en algoritmos simples que pueden ser fácilmente implementados en una computadora; por lo que en realidad son generadores de números pseudoaleatorios.
Números aleatorios en Python
En Python el módulo random nos proporciona un rápido generador de números pseudoaleatorios basado en el algoritmo Mersenne Twister; el cual genera números con una distribución casi uniforme y un período grande, haciéndolo adecuado para una amplia gama de aplicaciones. Veamos un pequeño ejemplo.
# Utilizando random para genera números aleatorios.
import random
random.seed(1984) # semilla para replicar la aleatoriedad
random.random() # primer llamado a random
0.36352835585530807
random.random() # segundo llamado a random
0.49420568181919666
for i in range(5):
print(random.random()) # 5 números aleatorios
0.33961008717180197
0.21648780903913534
0.8626522767441037
0.8493329421213219
0.38578540884489343
# volviendo a llamar a seed para replicar el mismo resultado aleatorio.
random.seed(1984)
for i in range(7):
print(random.random()) # Mismos resultados que arriba.
0.36352835585530807
0.49420568181919666
0.33961008717180197
0.21648780903913534
0.8626522767441037
0.8493329421213219
0.38578540884489343
En este ejemplo podemos ver como la función random genera números aleatorios entre 0 y 1, también podemos ver como con el uso de seed podemos replicar el comportamiento aleatorio.
Elegir un buen generador de números aleatorios
Existe una gran variedad de generadores de números aleatorios que podemos elegir; pero elegir un buen generador de números aleatorios es como elegir un coche nuevo: para algunas personas o aplicaciones la velocidad es primordial, mientras que para otros la robustez y la fiabilidad son más importantes. Para la simulación de Monte-Carlo las propiedades distributivas de los generadores aleatorios es primordial, mientras que en la criptografía la imprevisibilidad es crucial. Por tal motivo, el generador que vayamos a elegir dependerá de la aplicación que le vayamos a dar.
Monte-Carlo en acción
Los Métodos de Monte-Carlo se basan en la analogía entre probabilidad y volumen. Las matemáticas de las medidas formalizan la noción intuitiva de probabilidad, asociando un evento con un conjunto de resultados y definiendo que la probabilidad del evento será el volumen o medida relativa del universo de posibles resultados. Monte-Carlo usa esta identidad a la inversa, calculando el volumen de un conjunto interpretando el volumen como una probabilidad. En el caso más simple, esto significa muestrear aleatoriamente un universo de resultados posibles y tomar la fracción de muestras aleatorias que caen en un conjunto dado como una estimación del volumen del conjunto. La ley de grandes números asegura que esta estimación converja al valor correcto a medida que aumenta el número de muestras. El teorema del límite central proporciona información sobre la magnitud del probable error en la estimación después de un número finito de muestras. En esencia podemos decir que el Método de Monte-Carlo consiste en calcular o aproximar ciertas expresiones a través de adivinarlas con la ayuda de dibujar una cantidad normalmente grande de números aleatorios. Veamos como funciona con un ejemplo, calculemos el área de un círculo de radio 1; lo que es lo mismo a decir que aproximemos el valor de \(\pi\).
Ver Código
# <!-- collapse=True -->
# importando modulos necesarios
import matplotlib.pyplot as plt
import numpy as np # importando numpy
import pandas as pd # importando pandas
from scipy import stats
np.random.seed(1984) # para poder replicar el random
%matplotlib inline
# Ejemplo: Aproximando el valor de pi - área de un círculo de
# radio = 1.
def mc_pi_aprox(N=10000):
plt.figure(figsize=(8,8)) # tamaño de la figura
x, y = np.random.uniform(-1, 1, size=(2, N))
interior = (x**2 + y**2) <= 1
pi = interior.sum() * 4 / N
error = abs((pi - np.pi) / pi) * 100
exterior = np.invert(interior)
plt.plot(x[interior], y[interior], 'b.')
plt.plot(x[exterior], y[exterior], 'r.')
plt.plot(0, 0, label='$\hat \pi$ = {:4.4f}\nerror = {:4.4f}%'
.format(pi,error), alpha=0)
plt.axis('square')
plt.legend(frameon=True, framealpha=0.9, fontsize=16)
mc_pi_aprox()

# con 1000000 experimentos
mc_pi_aprox(N=100000)
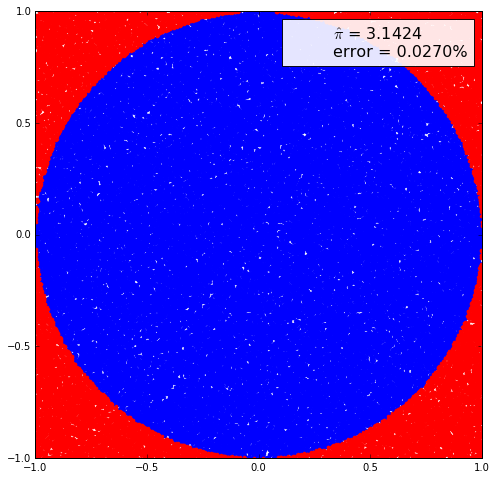
Como vemos en este ejemplo, para calcular el área del círculo realizamos un gran número de experimentos aleatorios, en el primer ejemplo utilizamos 10,000 experimentos; y luego calculamos el área obteniendo una media aritmética de los valores que caen dentro de la superficie del círculo. Debemos hacer notar que incluso utilizando un gran número de experimentos aún así en el primer ejemplo no logramos obtener los primeros dos decimales correctos; recién en el segundo ejemplo, cuando utilizamos 100,000 experimentos logramos obtener los primeros dos dígitos correctos; esto demuestra que el Método de Monte-Carlo en su versión más cruda tarda bastante en converger.
Técnicas de reducción de varianza
Existen varias técnicas generales para la reducción de la varianza, estos métodos mejoran la precisión y la tasa de convergencia de la integración por medio del Método de Monte-Carlo sin aumentar el número de experimentos. Algunas de estas técnicas son:
- Muestreo de importancia: La idea principal detrás del Muestreo de importancia es simplemente encontrar una distribución para la variable aleatoria subyacente que asigne una alta probabilidad a aquellos valores que son importantes para calcular la cantidad que nos interesa determinar.
- Muestreo estratificado: El principal principio subyacente al Muestreo estratificado es natural: tomar una muestra de una pequeña subpoblación que refleje las propiedades del total de la población tanto como sea posible.
- Variantes de control: El método de las Variantes de control explota la información sobre los errores en las estimaciones de las cantidades conocidas para reducir el error de una estimación de una cantidad desconocida.
- Variaciones antitéticas: El método de las Variaciones antitéticas es el método de reducción de la varianza, más fácil. Se basa en la idea de combinar una selección aleatoria de puntos con una opción sistemática. Su principal principio es la reducción de la varianza, mediante la introducción de la simetría.
Excede al alcance de este artículo el profundizar en cada una de estas técnicas, pueden encontrar un análisis más detallado de las mismas en el siguiente enlace (en inglés).
Métodos de Monte-Carlo via cadenas de Markov
El desarrollo de los métodos de Monte-Carlo via cadenas de Markov, o MCMC por sus siglas en inglés, es sin duda uno de los mayores avances en el enfoque computacional de la estadística. Muchos de los problemas que son intratables utilizando un enfoque analítico a menudo pueden ser resueltos utilizando alguna forma de MCMC, incluso aunque se trate de problemas en varias dimensiones. Las técnicas MCMC se aplican para resolver problemas de integración y optimización en grandes espacios dimensionales. Estos dos tipos de problemas desempeñan un papel fundamental en machine learning, física, estadística, econometría y el análisis de decisiones.
¿Qué es una cadena de Markov?
Una cadena de Markov es un objeto matemático que consiste en una secuencia de estados y un conjunto de probabilidades que describen las transiciones entre esos estados. La característica principal que tiene esta cadena es que la probabilidad de moverse a otros estados depende solamente del estado actual. Dada una cadena, se puede realizar una caminata aleatoria eligiendo un punto de partida y moviéndose a otros estados siguiendo las probabilidades de transición. Si de alguna manera encontramos una cadena de Markov con transiciones proporcionales a la distribución que queremos probar, el muestreo se convierte simplemente en una cuestión de moverse entre los estados de esta cadena.
Caminata aleatoria en un grafo
Una cadena de Markov puede ser ilustrada con el siguiente grafo, el cual representa una cadena de Markov de cuatro estados.

Los estados de la cadena se representan como los nodos del grafo, una arista de dirección se extiende de un nodo \(x\) hacia otro nodo \(y\) si la transición de \(x\) hacia \(y\) es posible en una iteración. Cada una de estas aristas de dirección tienen una probabilidad asociada \(P_{xy}\); esta es la probabilidad de que el nodo sea elegido en la siguiente iteración cuando la cadena se encuentra en el estado \(x\). La cadena comienza en algún estado, digamos \(X_0\), que puede ser elegido en forma aleatoria de acuerdo con una distribución inicial o simplemente asignado en forma arbitraria. Desde allí, la cadena se mueve de un estado a otro en cada iteración según las probabilidades de transición del nodo vecino.
Representación matricial
Como alternativa a la representación en forma de grafo, la cadena antes descripta también puede ser representada por una matriz \(P = (p_{xy})\) de las probabilidades \(p_{xy}\) de transición de un estado $x$ a un estado \(y\) en una iteración de la cadena. Esta matriz es llamada matriz de transición y tiene la característica que todas sus filas deben sumar 1. Por ejemplo, la matriz de transición de nuestro ejemplo sería la siguiente:
$$ P = \begin{bmatrix} p_{11} & p_{12} & 0 & p_{14} \\ p_{21} & 0 & p_{23} & 0 \\ p_{31} & 0 & 0 & p_{34} \\ 0 & 0 & p_{43} & p_{44} \end{bmatrix} $$Esta formulación de matriz es mucho más que una descripción tabular de la cadena; también es una herramienta de cálculo. Ya que si por ejemplo definimos a \(p_t\) como el vector de probabilidad de una variable aleatoria \(X_t\); entonces podemos calcular \(p_{t + 1}\) como una multiplicación de matrices
$$ p_{t + 1} = p_t \cdot P, \hspace{1cm} t= 1, 2, \dots $$La distribución invariante
Una de las características generales de las cadenas de Markov es que pueden poseer una distribución invariante, tomemos por ejemplo la siguiente representación matricial de una cadena de Markov:
$$ P = \begin{bmatrix} 0.3 & 0.2 & 0.5 \\ 0.4 & 0.3 & 0.3 \\ 0.3 & 0.4 & 0.3 \end{bmatrix} $$Si comenzamos en el primer estado de la cadena, podemos obtener \(p_1\) del siguiente modo:
$$ p_1 = \begin{bmatrix} 1 & 0 & 0 \end{bmatrix} \cdot \begin{bmatrix} 0.3 & 0.2 & 0.5 \\ 0.4 & 0.3 & 0.3 \\ 0.3 & 0.4 & 0.3 \end{bmatrix} = \begin{bmatrix} 0.3 & 0.2 & 0.5 \end{bmatrix} $$Ahora que ya obtuvimos \(p_1\), podemos continuar y obtener \(p_2\):
$$ p_2 = p_1 P = \begin{bmatrix} 0.3 & 0.2 & 0.5 \end{bmatrix} \cdot \begin{bmatrix} 0.3 & 0.2 & 0.5 \\ 0.4 & 0.3 & 0.3 \\ 0.3 & 0.4 & 0.3 \end{bmatrix} = \begin{bmatrix} 0.32 & 0.22 & 0.36 \end{bmatrix} $$Si continuamos con este proceso en forma recursiva, veremos que la distribución tiende hacía un límite, este límite es su distribución invariante.
$$ \begin{eqnarray} p_3 = p_2 P = \begin{bmatrix} 0.332 & 0.304 & 0.364 \end{bmatrix}, \\\ p_4 = p_3 P = \begin{bmatrix} 0.3304 & 0.3032 & 0.3664 \end{bmatrix}, \\\ p_5 = p_4 P = \begin{bmatrix} 0.33032 & 0.3036 & 0.36608 \end{bmatrix}, \\\ \dots \hspace{1cm} \dots \\\ p_{10} = p_9 P = \begin{bmatrix} 0.330357 & 0.303571 & 0.366072 \end{bmatrix} \end{eqnarray} $$Veamos el ejemplo con la ayuda de Python para que quede más claro.
# Ejemplo distribución invariante
P = np.array( [[0.3, 0.2, 0.5],
[0.4, 0.3, 0.3 ],
[0.3, 0.4, 0.3]] )
P
array([[ 0.3, 0.2, 0.5],
[ 0.4, 0.3, 0.3],
[ 0.3, 0.4, 0.3]])
p1 = np.array( [1, 0, 0] )
for i in range(1, 12):
p_i = p1 @ P
print('p_{0:} = {1:}'.format(i, p_i))
p1 = p_i
p_1 = [ 0.3 0.2 0.5]
p_2 = [ 0.32 0.32 0.36]
p_3 = [ 0.332 0.304 0.364]
p_4 = [ 0.3304 0.3032 0.3664]
p_5 = [ 0.33032 0.3036 0.36608]
p_6 = [ 0.33036 0.303576 0.366064]
p_7 = [ 0.3303576 0.3035704 0.366072 ]
p_8 = [ 0.33035704 0.30357144 0.36607152]
p_9 = [ 0.33035714 0.30357145 0.36607141]
p_10 = [ 0.33035714 0.30357143 0.36607143]
p_11 = [ 0.33035714 0.30357143 0.36607143]
Como vemos, luego de 12 iteraciones la distribución alcanza su límite y ya no cambian los resultados. Hemos alcanzado la distribución invariante!
El algoritmo Metropolis-Hastings
Uno de los métodos MCMC más populares es el algoritmo Metropolis-Hastings; de hecho la mayoría de los algoritmos de MCMC pueden ser interpretados como casos especiales de este algoritmo. El algoritmo Metropolis-Hastings esta catalogado como uno de los 10 algoritmos más importantes y más utilizados en ciencia e ingeniería en los últimos veinte años.Se encuentra en el corazón de la mayoría de los métodos de muestreo MCMC. El problema básico que intenta resolver el algoritmo Metropolis-Hastings es proporcionar un método para generar muestras de alguna distribución genérica, \(P(x)\). La idea es que en muchos casos, podemos saber cómo escribir la ecuación para la distribución de probabilidad \(P(x)\), pero no sabemos cómo generar muestras aleatorias de la misma. Entonces la idea básica detrás de este algoritmo es la de construir una cadena de Markov cuya distribución invariante sea la distribución de muestreo que deseamos, es decir \(P(x)\). En principio, esto puede parecer bastante complicado, pero la flexibilidad inherente en la elección de las probabilidades de transición lo hacen más simple de lo que parece.
¿Cómo funciona el algoritmo?
El algoritmo funciona del siguiente modo. Supongamos que el estado actual de la cadena de Markov es \(x_n\), y queremos generar \(x_{n + 1}\). De acuerdo con el algoritmo Metropolis-Hastings, la generación de \(x_{n + 1}\) es un proceso en dos etapas. La primera etapa consiste en generar un candidato, que denominaremos \(x^* \). El valor de \(x^* \) se genera a partir de la distribución propuesta, denotada \(Q (x^* | x_n)\), la cual depende del estado actual de la cadena de Markov , \(x_n\). Existen algunas limitaciones técnicas menores sobre la distribución propuesta que podemos utilizar, pero en su mayor parte puede ser cualquier cosa que deseemos. Una forma típica de hacerlo es utilizar una distribución normal centrada en el estado actual \(x_n\). Es decir,
$$ x^*|x_n \sim Normal(x_n, \sigma^2)$$La segunda etapa es la de aceptación-rechazo. Lo primero que debemos hacer en este paso es calcular la probabilidad de aceptación \(A(x_n \rightarrow x^*)\), la cual estará dada por:
$$A(x_n \rightarrow x^*) = \min \left(1, \frac{P(x^*)}{P(x_n)} \cdot \frac{Q(x_n | x^*)}{Q(x^* | x_n)} \right) $$Muy bien. Ahora que tenemos el candidato \(x^* \) y hemos calculado la probabilidad de aceptación \( A(x_n \rightarrow x^* ) \), es tiempo de decidir aceptar al candidato (en cuyo caso se establecemos \( x_{n + 1} = x^* \) ); o rechazar al candidato (en cuyo caso estableceremos \( x_{n + 1} = x_n \)). Para tomar esta decisión, generamos un número aleatorio (uniformemente distribuido) entre 0 y 1, que denominaremos \(u\). Entonces:
$$x_{n + 1} = \left\{ \begin{array}{ll} x^* & \mbox{si } u \leq A(x_n \rightarrow x^*)\\ x_n & \mbox{si } u > A(x_n \rightarrow x^*) \end{array} \right. $$Y esto es en esencia como funciona el algoritmo Metropolis-Hastings!
Veamos un pequeño ejemplo en Python:
# Ejemplo algoritmo metropolis
def metropolis(func, steps=10000):
"""A very simple Metropolis implementation"""
muestras = np.zeros(steps)
old_x = func.mean()
old_prob = func.pdf(old_x)
for i in range(steps):
new_x = old_x + np.random.normal(0, 0.5)
new_prob = func.pdf(new_x)
aceptacion = new_prob / old_prob
if aceptacion >= np.random.random():
muestras[i] = new_x
old_x = new_x
old_prob = new_prob
else:
muestras[i] = old_x
return muestras
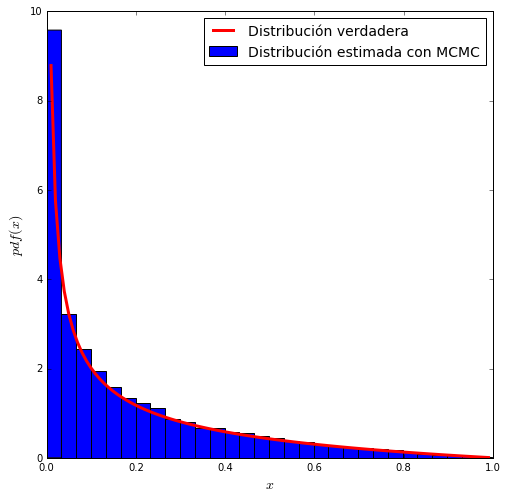
# distribución beta
func = stats.beta(0.4, 2)
samples = metropolis(func=func, steps=100000)
x = np.linspace(0.01, .99, 100)
y = func.pdf(x)
plt.figure(figsize=(8,8))
plt.xlim(0, 1)
plt.plot(x, y, 'r-', lw=3, label='Distribución verdadera')
plt.hist(samples, bins=30, normed=True, label='Distribución estimada con MCMC')
plt.xlabel('$x$', fontsize=14)
plt.ylabel('$pdf(x)$', fontsize=14)
plt.legend(fontsize=14)
plt.show()
# distribución normal
func = stats.norm(0.4, 2)
samples = metropolis(func=func)
x = np.linspace(-6, 10, 100)
y = func.pdf(x)
plt.figure(figsize=(8,8))
plt.xlim(-6, 6)
plt.plot(x, y, 'r-', lw=3, label='Distribución verdadera')
plt.hist(samples, bins=30, normed=True, label='Distribución estimada con MCMC')
plt.xlabel('$x$', fontsize=14)
plt.ylabel('$pdf(x)$', fontsize=14)
plt.legend(fontsize=14)
plt.show()
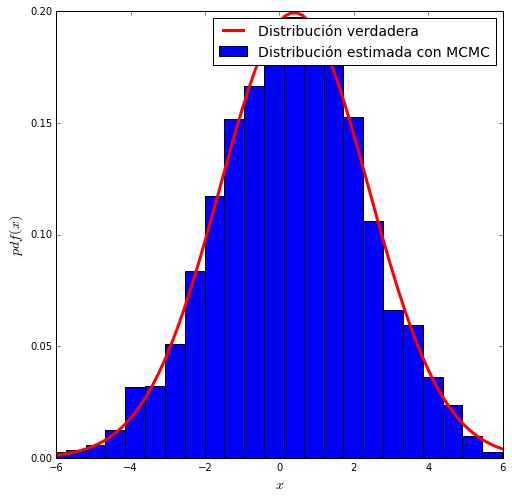
como vemos, las distribuciones estimadas utilizando MCMC se acercan bastante a las distribuciones reales.
Otros métodos MCMC
Además del algoritmo Metropolis-Hastings existen otros algoritmos de muestreo que utilizan los métodos MCMC. Algunos de ellos son:
-
Muestreo de Gibbs, el cual es un caso especial del algoritmo Metropolis-Hastings.
-
Monte-Carlo Hamiltoniano o híbrido, el cual reduce la correlación entre los sucesivos estados de muestreo usando una evolución Hamiltoniana.
-
Muestreo de rebanada o Slice sampler, este método se basa en la observación de que para muestrear una variable aleatoria se pueden tomar muestras en forma uniforme de la región debajo del gráfico de su función de densidad.
-
NUTS o No U turn sampler, el cual es una extensión del algoritmo híbrido de Monte-Carlo que logra incluso mayor eficiencia.
Con esto concluye este paseo por los Métodos de Monte-Carlo y la estadística computacional, espero que les haya parecido interesante y les sea de utilidad en sus proyectos.
Saludos!
Este post fue escrito utilizando IPython notebook. Pueden descargar este notebook o ver su version estática en nbviewer.