Introducción a la inferencia causal con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, Analisis de datos y Python. El contenido esta bajo la licencia BSD.

“…lo que llamamos azar es nuestra ignorancia de la compleja maquinaria de la causalidad”
Introducción
¿Por qué?…Esta eterna pregunta es una de las más fundamentales. La solemos formular incontables veces al día! El ser humano parece tener una infinita curiosidad por entender el por qué pasan las cosas, y nuestro cerebro parece estar especialmente diseñado para encontrar esas causas…o inventarlas.
La causalidad es la conexión más fundamental en el universo. Sin ella, no hay responsabilidad moral: ninguno de nuestros pensamientos estaría relacionado con nuestras acciones y ninguna de nuestras acciones con consecuencias. Tampoco tendríamos un sistema legal porque la culpa reside solo en alguien que ha causado lesiones o daños. No habría ciencia ni tecnología.
Richard feynman definía a la Ciencia como un método para intentar responder preguntas del tipo “Si hago esto, ¿qué pasará?". Ciencia no es sobre belleza, verdad, justicia, sabiduría o ética; es algo eminemente práctico. Es sobre realizar experimentos, probar, ver los resultados y adquirir la mayor cantidad información de esas experiencias. Desde pequeños, aprendemos que el mundo no está compuesto solo de datos o hechos; sino que éstos hechos están interconectados por una intrincada red de relaciones de causa-efecto. Cualquier intervención que hagamos en el mundo que nos rodea se basa en la existencia de conexiones causales que son al menos predecibles en cierto grado. Es la causalidad la base de esta predicción y también la explicación.
Escalera del pensamiento causal
Según Judea Pearl, uno de los padres de la formalización del razonamiento causal, nuestra habilidad para organizar el conocimiento sobre el mundo que nos rodea en causas y efectos, se basa en 3 habilidades cognitivas: ver, hacer e imaginar. Para explicar como estas habilidades nos ayudan a construir las explicaciones causales, recurre a la metáfora de una escalera.

El primero escalón, ver u observar, implica la detección de regularidades en nuestro ambiente y es compartida por muchos animales. El segundo escalón, hacer, implica predecir el (los) efecto (s) de alteraciones deliberadas del medio ambiente y elegir entre éstas alteraciones para producir un resultado deseado. Solo un pequeño puñado de especies han demostrado elementos de esta habilidad. El uso de herramientas, siempre que sea intencional y no solo accidental, podría tomarse como una señal de alcanzar este segundo nivel. Sin embargo, incluso los usuarios de herramientas no necesariamente poseen una “teoría” de su herramienta que les dice por qué funciona y qué hacer cuando no lo hace. Para eso, se debe haber alcanzado un nivel de comprensión más alto, eso lo permite imaginar. Fue principalmente este tercer nivel el que nos preparó para nuevas revoluciones en agricultura y ciencia y condujeron a un repentino y drástico cambio en el impacto de nuestra especie en el planeta.
Diagramas Causales: Dibuja el camino hacia la verdad
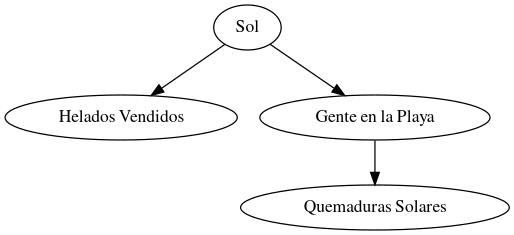
A veces, es más fácil entender las relaciones cuando las dibujamos. Los diagramas causales (o DAGs) son una forma visual de mapear las conexiones entre variables. Los diagramas causales son simplemente imágenes de puntos y flechas que resumen nuestro conocimiento científico existente. Los puntos representan las variables de interés, y las flechas representan relaciones causales conocidas o sospechadas entre esas variables.
Pensemos por ejemplo en un diagrama donde el sol provoca tanto más helados vendidos como más gente en la playa (y más casos de quemaduras solares). Aquí podríamos caer en la trampa de pensar que el helado es el culpable de las quemaduras. Sin embargo, si dibujamos el diagrama, podemos ver más claramente las relaciones entre las variables.
# Dibujando el DAG con Python
from graphviz import Digraph
def dibujar_dag():
dot = Digraph()
dot.edge('Sol', 'Helados Vendidos')
dot.edge('Sol', 'Gente en la Playa')
dot.edge('Gente en la Playa', 'Quemaduras Solares')
dot.render('dag_causal', format='png', cleanup=False)
return dot
# Ejecutar función para dibujar el DAG
dibujar_dag()
Variables de Confusión: El enemigo invisible
Las variables de confusión son las responsables de muchos malentendidos en la inferencia causal. Estas variables afectan tanto la causa como el efecto, creando una falsa impresión de relación. Son variables ocultas que pasomos por alto y confunden los resultados de nuestro modelo causal.
Por ejemplo, ¿el café mejora la salud del corazón o simplemente las personas que toman café tienden a hacer más ejercicio? El ejercicio podría ser la variable oculta que está confundiendo la relación.
La Paradoja de Simpson: Cuando los datos nos engañan
La paradoja de Simpson ocurre cuando una tendencia que aparece en varios grupos desaparece o se invierte al analizar los datos en conjunto. Esta paradoja es una gran advertencia para cualquiera que realice inferencia causal. Para entenderla mejor, recurramos a su ejemplo clásico.
Ejemplo clásico: Imagina que dos hospitales tratan pacientes con una nueva terapia. Al analizar los datos de cada hospital por separado, parece que la terapia es efectiva. Sin embargo, al combinar los datos de ambos hospitales, el efecto se invierte y la terapia parece perjudicial. ¿Cómo es posible?
Esto puede suceder porque los hospitales pueden tener diferentes tasas de admisión para pacientes graves. Si un hospital recibe más pacientes críticos, sus resultados pueden parecer peores en general, a pesar de que la terapia sea beneficiosa.
Lección clave: Siempre debemos analizar si hay subgrupos ocultos que podrían estar sesgando nuestros resultados. Los diagramas causales y la identificación de variables de confusión son esenciales para evitar caer en esta trampa.
AB Testing y Randomizacion: Las herramientas de oro para la Causalidad
La herramienta por excelencia para probar si una acción específica causa un resultado, es el AB Testing. Es una técnica muy sencilla que consite en realizar experimentos aleatorios entre una variante A y una variante B.
Imaginemos que tienemos una tienda online y quieremos saber qué botón de “Comprar” funcionará mejor:
- Un botón verde que dice “Comprar”
- Un botón rojo que dice "¡Llévalo ya!”
El AB testing es como hacer un experimento donde:
- Divides a tus visitantes en dos grupos al azar (esto es la randomización)
- Al grupo A les muestras el botón verde
- Al grupo B les muestras el botón rojo
- Después de un tiempo, comparas cuál botón generó más ventas
La randomización (división al azar) es super importante porque nos asegura que cualquier diferencia entre los grupos se debe a la intervención que queremos probar y no a otros factores ocultos. Sin randomización, los resultados pueden estar sesgados. Por ejemplo, si mostraramos el botón verde solo por las mañanas y el rojo por las tardes, no sabríamos si las diferencias en ventas son por el color del botón o porque la gente compra más a ciertas horas del día.
Ejemplo práctico con DoWhy: Analizando la relación entre estudio y notas
Por último para cerrar y asimilar los conceptos, usaremos la librería DoWhy en Python para analizar un ejemplo práctico: Intentaremos responder la pregunta ¿Estudiar más; causa mejores notas?
import dowhy
from dowhy import CausalModel
import pandas as pd
import numpy as np
# Simulación de datos
data = pd.DataFrame({
"horas_estudio": np.random.normal(5, 2, 1000),
"notas": np.random.normal(70, 10, 1000),
"inteligencia": np.random.normal(100, 15, 1000) # Variable de confusión
})
# Convertimos horas de estudio a binario (0: menos de 5 horas, 1: 5 o más horas)
data["horas_estudio"] = (data["horas_estudio"] >= 5).astype(int)
# Añadimos relación causal artificial
data["notas"] += data["horas_estudio"] * 10 + data["inteligencia"] * 0.5
# Definir el modelo causal
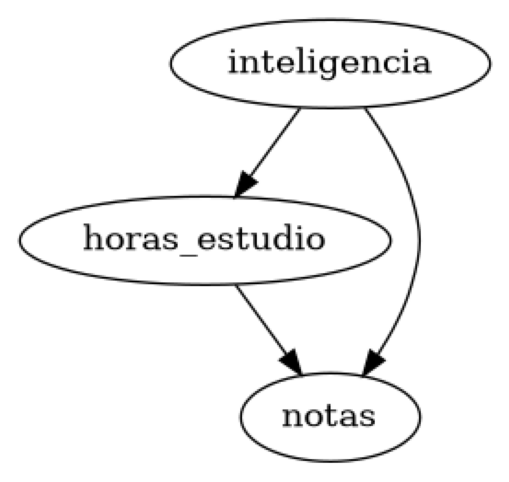
modelo = CausalModel(
data=data,
treatment="horas_estudio",
outcome="notas",
common_causes=["inteligencia"] # Añadimos la confusión
)
modelo.view_model()
# Estimar el efecto causal
estimacion = modelo.identify_effect()
resultado = modelo.estimate_effect(estimacion, method_name="backdoor.propensity_score_matching")
print("Efecto causal estimado: ", resultado.value)
Efecto causal estimado: 9.036238221417607
Este resultado nos indica que, en promedio, los estudiantes que estudian 5 horas o más (frente a los que estudian menos de 5 horas) obtienen aproximadamente 9.03 puntos adicionales en sus notas. Si buscamos mejorar las calificaciones, incrementar el tiempo de estudio puede ser una estrategia efectiva. Es importante tener en cuenta que este resultado se basa en datos simulados y el modelo está diseñado con un efecto causal artificial, por lo que no debe ser tomado como un reflejo de la realidad. Aunque siempre es recomendado dedicar una buena parte del tiempo al estudio si queremos mejorar las calificaciones! 😉
Saludos!
Este post fue escrito por Raúl E. López Briega utilizando Jupyter notebook. Pueden descargar este notebook o ver su version estática en nbviewer.