Análisis de datos cuantitativos con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, análisis de datos y python. El contenido esta bajo la licencia BSD.

Introducción
En mi artículo anterior, Análisis de datos categóricos con Python, mencione la importancia de reconocer los distintos tipos de datos con que nos podemos encontrar al realizar análisis estadísticos y vimos también como podemos trabajar con los datos categóricos. En esta oportunidad, vamos a ver como podemos manipular, interpretar y obtener información de los datos cuantitativos.
Recordemos que las variables cuantitativas son variables medidas en una escala numérica. Altura, peso, tiempo de respuesta, la calificación subjetiva del dolor, la temperatura, y la puntuación en un examen, son ejemplos de variables cuantitativas. Las variables cuantitativas se distinguen de las variables categóricas (también llamadas cualitativas) como el color favorito, religión, ciudad de nacimiento, y el deporte favorito; en las que no hay un orden o medida involucrados.
Analizando datos cuantitativos con Python
Para los ejemplos de este artículo, vamos a trabajar con el dataset faithful, el cual consiste en una colección de observaciones sobre las erupciones del géiser Old Faithful en el parque nacional Yellowstone de los Estados Unidos. La información que contiene este dataset es la siguiente:
Ver Código
# <!-- collapse=True -->
# importando modulos necesarios
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
import pandas as pd
import seaborn as sns
from pydataset import data
# parametros esteticos de seaborn
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
faithful = data('faithful')
faithful.head(10)
| eruptions | waiting | |
|---|---|---|
| 1 | 3.600 | 79 |
| 2 | 1.800 | 54 |
| 3 | 3.333 | 74 |
| 4 | 2.283 | 62 |
| 5 | 4.533 | 85 |
| 6 | 2.883 | 55 |
| 7 | 4.700 | 88 |
| 8 | 3.600 | 85 |
| 9 | 1.950 | 51 |
| 10 | 4.350 | 85 |
Como podemos ver, faithful es un dataset bastante simple que solo contiene observaciones de dos variables; la primera, que se llama eruptions, contiene la información de la duración de la erupción del géiser; mientras que la segunda, se llama waiting y contiene la información sobre el tiempo de espera para la siguiente erupción del géiser.
Al igual de como comentábamos cuando analizamos datos categóricos, lo primero que deberíamos intentar hacer es crear una imagen que represente de la mejor manera posible a nuestros datos, ya que nuestro cerebro tiende a procesar mejor la información visual. Para el caso de las variables cuantitativas, un buen candidato para comenzar a hacernos una imagen de lo que nuestros datos representan, son los histogramas.
Histogramas
Para las variables cuantitativas, a diferencia de lo que pasaba con las variables categóricas, no existe una forma obvia de agrupar los datos; por tal motivo lo que se suele hacer es, dividir los posibles valores en diferentes contenedores del mismo tamaño y luego contar el número de casos que cae dentro de cada uno de los contenedores. Estos contenedores junto con sus recuentos, nos proporcionan una imagen de la distribución de la variable cuantitativa y constituyen la base para poder graficar el histograma. Para construir el gráfico, simplemente debemos representar a los recuentos como barras y graficarlas contra los valores de cada uno de los contenedores.
Con Python podemos representar fácilmente el histograma de la variable eruptions utilizando el método hist del DataFrame de Pandas del siguiente modo:
# histograma duración de erupciones con 8 barras
faithful['eruptions'].hist(bins=8)
plt.xlabel("Duración en minutos")
plt.ylabel("Frecuencia")
plt.show()
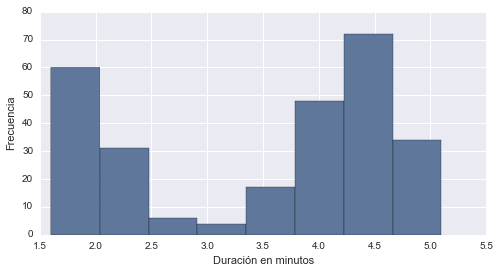
Como podemos ver con este gráfico, la duración más frecuente de las erupciones del géiser ronda en alrededor de cuatro minutos y medio. Una cosa que debemos hacer notar es que en los histogramas, los contenedores dividen a todos los valores de la variable cuantitativa, por lo que no deberíamos encontrar espacios entre las barras (a diferencia de lo que pasaba con los gráficos de barras que vimos en el artículo anterior). Cualquier espacio entre las barras es una brecha en los datos, que nos indica un región para la que no existen valores.
Distribución de frecuencia
Un tema íntimamente relacionado con los histogramas son las tablas de distribución de frecuencia, en definitiva los histogramas no son más que gráficos de tablas de distribución de frecuencia. La distribución de frecuencia de una variable cuantitativa consiste en un resumen de la ocurrencia de un dato dentro de una colección de categorías que no se superponen. Estas categorías las vamos a poder armar según nuestra conveniencia y lo que queramos analizar. Por ejemplo si quisiéramos armar la distribución de frecuencia de la variable eruptions podríamos realizar las siguiente manipulaciones con Pandas:
# Distribución de frecuencia.
# 1ro creamos un rango para las categorías.
contenedores = np.arange(1.5, 6., 0.5)
# luego cortamos los datos en cada contenedor
frec = pd.cut(faithful['eruptions'], contenedores)
# por último hacemos el recuento de los contenedores
# para armar la tabla de frecuencia.
tabla_frec = pd.value_counts(frec)
tabla_frec
(4, 4.5] 75
(1.5, 2] 55
(4.5, 5] 54
(2, 2.5] 37
(3.5, 4] 34
(3, 3.5] 9
(2.5, 3] 5
(5, 5.5] 3
dtype: int64
Como nos nuestra esta tabla de distribución de frecuencia, la duración que más veces ocurre para las erupciones, se encuentran en el rango de 4 a 4.5 minutos.
Diagrama de tallos y hojas
Los histogramas nos permiten apreciar la distribución de los datos de una forma sencilla, pero los mismos no nos muestran los valores del dataset en sí mismos. Para solucionar esto, existe el diagrama de tallos y hojas, el cual es similar al histograma pero nos muestra los valores individuales de nuestro dataset. Para que quede más claro, vemos un ejemplo sencillo. Supongamos que tenemos una muestra sobre el ritmo cardíaco de 24 mujeres, las observaciones son las siguientes:
pulso = [88, 80, 76, 72, 68, 56, 64, 60, 64, 68, 64, 68,
72, 76, 80, 84, 68, 80, 76, 72, 84, 80, 72, 76 ]
Podríamos graficar el histograma de estas observaciones del siguiente modo:
plt.hist(pulso, bins=7)
plt.xlabel("latidos por minuto")
plt.ylabel("N° de mujeres")
plt.show()
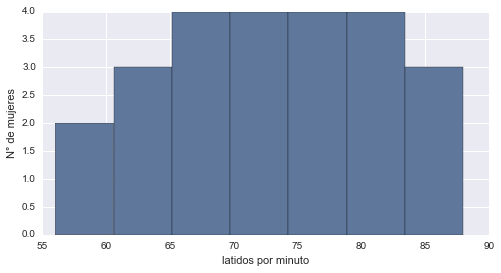
Este histograma nos muestra la forma en que se distribuyen los datos, pero no nos muestra los datos individuales. Para esto podríamos graficar su diagrama de tallos y hojas de la siguiente manera:
# Diagrama de tallos y hojas
def tallos(d):
"Genera un simple diagramas de tallos y hojas"
l,t=np.sort(d),10
O=range(int(l[0]-l[0]%t),int(l[-1]+11),t)
I=np.searchsorted(l,O)
for e,a,f in zip(I,I[1:],O):
print('%3d|'%(f/t),*(l[e:a]-f),sep='')
tallos(pulso)
5|6
6|04448888
7|22226666
8|0000448
Como vemos, la distribución del diagrama de tallos y hojas es similar a la del histograma, pero en este caso si podemos ver los valores de nuestras observaciones. El diagrama se lee así: Por un lado tenemos las decenas de los latidos, las cuales constituyen los tallos de nuestro diagrama (los valores antes del pipe o barra vertical “|”) y luego vamos agrando hojas a estos tallos , representadas por las unidades de cada latido. De esta forma 5|6, significa que solo aparece el valor 56 una sola vez, en cambio 8|0000, significa que tenemos el valor 80 observado en 4 oportunidades.
Diagrama de dispersión
Hasta aquí venimos graficando únicamente una sola variable cuantitativa pero ¿qué pasa si queremos trabajar con dos variables? Para estos casos existe el diagrama de dispersión. El diagrama de dispersión es una de las formas más comunes que existen para visualizar datos y constituye una de las mejores forma de observar relaciones entre dos variables cuantitativas. Veremos que se puede observar un montón de cosas por el solo hecho de mirar. Este diagrama es una de las mejores formas de visualizar las asociaciones que pueden existir entre nuestros datos.
El diagrama de dispersión empareja los valores de dos variables cuantitativas y luego los representa como puntos geométricos dentro de un diagrama cartesiano. Por ejemplo, volviendo a nuestro dataset faithful, podríamos emparejar a las variables eruptions y waiting en la misma observación como coordenadas (x, y) y luego graficarlas en el eje cartesiano. Con la ayuda de Python podríamos generar el diagrama de dispersión del siguiente modo:
# diagrama de dispersión
disp= faithful.plot(kind='scatter', x='eruptions', y='waiting')
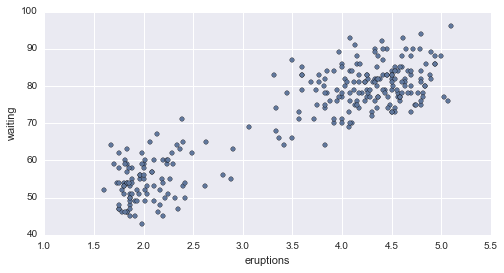
Como podemos ver con solo observar la dispersión de los datos parece existir una relación lineal entre los datos de este dataset.
Medidas de tendencia central
Una vez que ya nos dimos una buena idea visual de como se distribuyen los datos y de las relaciones que pueden existir entre los mismos, podemos pasar a calcular medidas numéricas propias de la estadística descriptiva. En general, suele ser interesante conocer cual puede ser el promedio o valor central al que tiende la distribución de nuestros datos, para esto se utilizan las medidas de tendencia central, entre las que podemos encontrar a:
- La media aritmética
- La media ponderada
- La media geométrica
- La media armónica
- La mediana
- La media truncada
- La moda
Veamos como podemos calcularlas con Python:
Media aritmética
La media aritmética es el valor obtenido al sumar todos los datos y dividir el resultado entre el número total elementos. La calculamos con el método mean.
# media de variable eruptions
faithful['eruptions'].mean()
3.4877830882352936
Media ponderada
La media ponderada es apropiada cuando en un dataset cada dato tiene una importancia relativa (o peso) respecto de los demás. Como esta media no aplica para nuestro dataset no la vamos a calcular.
Media geométrica
La media geométrica es útil cuando queremos comparar cosas con propiedades muy diferentes; también es es recomendada para datos de progresión geométrica, para promediar razones, interés compuesto y números índices. Se calcula tomando la raíz n-ésima del producto de todos los datos. La calculamos con la función gmean de SciPy.
# media geometrica
stats.gmean(faithful['eruptions'])
3.2713131325361786
Media armónica
La media armónica promedia el número de elementos y los divide por la suma de sus inversos. La media armónica es siempre la media más baja y es recomendada para promediar velocidades. La calculamos con la función hmean de SciPy.
# media armónica
stats.hmean(faithful['eruptions'])
3.0389330499472611
Mediana
La mediana representa el valor de posición central en un conjunto de datos ordenados. La podemos calcular utilizando el método median de Pandas
# mediana
faithful['eruptions'].median()
4.0
Media truncada
La media truncada es una mezcla entre la media aritmética y la mediana. Para calcular el promedio previamente se descartan porciones en el extremo inferior y superior de la distribución de los datos. En Python podemos utilizar la función trim_mean de SciPy.
# media truncada, recortando el 10 superior e inferior
stats.trim_mean(faithful['eruptions'], .10)
3.5298073394495413
Moda
Por último, la moda es el valor que tiene mayor frecuencia absoluta. Son los picos que vemos en el histograma. Dependiendo de la la distribución de los datos puede existir más de una, como en el caso de la variable eruptions. La calculamos con el método mode.
# moda
faithful['eruptions'].mode()
0 1.867
1 4.500
dtype: float64
Medidas de dispersión
Las medidas de tendencia central no son las únicas medidas de resumen estadístico que podemos calcular; otras medidas también de gran importancia son las medidas de dispersión. Las medidas de dispersión, también llamadas medidas de variabilidad, muestran la variabilidad de una distribución, indicando por medio de un número si las diferentes puntuaciones de una variable están muy alejadas de la media. Cuanto mayor sea ese valor, mayor será la variabilidad, y cuanto menor sea, más homogénea será a la media. Así se sabe si todos los casos son parecidos o varían mucho entre ellos. Las principales medidas de dispersión son:
- La varianza
- El desvío estándar
- Los cuartiles
- La covarianza
- El coeficiente de correlación
Analicemos cada uno de ellos:
Varianza
La varianza intenta describir la dispersión de los datos. Se define como la esperanza del cuadrado de la desviación de dicha variable respecto a su media. Una varianza pequeña indica que los puntos de datos tienden a estar muy cerca de la media y por lo tanto el uno al otro, mientras que una varianza alta indica que los puntos de datos están muy distribuidos alrededor de la media y la una de la otra. La podemos calcular con el método var.
# varianza
faithful['eruptions'].var()
1.3027283328494705
Desvío estándar
El desvío estándar o desviación típica es una medida que se utiliza para cuantificar la cantidad de variación o dispersión de un conjunto de valores de datos. Un desvío estándar cerca de 0 indica que los puntos de datos tienden a estar muy cerca de la media del conjunto, mientras que un alto desvío estándar indica que los puntos de datos se extienden a lo largo de un rango amplio de valores. Se calcula como la raíz cuadrada de la varianza y con Pandas lo podemos obtener con el método std.
# desvio estándar
faithful['eruptions'].std()
1.1413712511052092
Cuartiles
Los cuartiles son los tres puntos que dividen el conjunto de datos en cuatro grupos iguales, cada grupo comprende un cuarto de los datos.El (Q1) se define como el número medio entre el número más pequeño y la mediana del conjunto de datos. El segundo cuartil (Q2) es la mediana de los datos. El tercer cuartil (Q3) es el valor medio entre la mediana y el valor más alto del conjunto de datos. Para dividir nuestro dataset en sus cuartiles utilizamos el método quantile.
# cuartiles
faithful['eruptions'].quantile([.25, .5, .75])
0.25 2.16275
0.50 4.00000
0.75 4.45425
dtype: float64
Un gráfico relacionado a los cuartiles y describe varias características importantes al mismo tiempo, tales como la dispersión y simetría es el diagrama de caja. Para su realización se representan los tres cuartiles y los valores mínimo y máximo de los datos, sobre un rectángulo, alineado horizontal o verticalmente. Podemos utilizar la función boxplot de Seaborn para generarlo.
# diagrama de cajas
cajas=sns.boxplot(list(faithful['eruptions']))
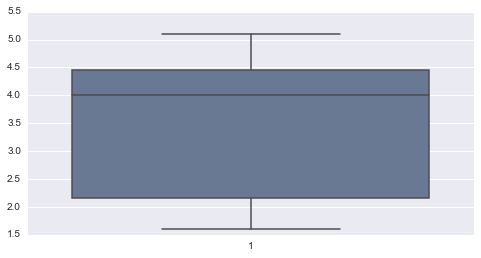
Hasta aquí hemos calculado medidas de dispersión para una sola variable, pero nuestro dataset tiene dos variables cuantitativas; veamos como podemos calcular medidas combinadas para la dos variables.
Covarianza
La covarianza es el equivalente de la varianza aplicado a una variable bidimensional. Es la media aritmética de los productos de las desviaciones de cada una de las variables respecto a sus medias.La covarianza indica el sentido de la correlación entre las variables; Si es mayor que cero la correlación es directa, en caso de ser menor, la correlación es inversa. La podemos calcular utilizando el método cov.
# covarianza
faithful.cov()
| eruptions | waiting | |
|---|---|---|
| eruptions | 1.302728 | 13.977808 |
| waiting | 13.977808 | 184.823312 |
Correlación
Por último, el coeficiente de correlación es una medida del grado de dependencia lineal entre dos variables. El coeficiente de correlación oscila entre -1 y 1. Un valor de 1 significa que una ecuación lineal describe la relación entre las dos variables a la perfección, con todos los puntos de datos cayendo sobre una línea recta de pendiente positiva. Un valor de -1 implica que todos los puntos de datos se encuentran en una línea con pendiente negativa. Un valor de 0 implica que no existe una correlación lineal entre las variables. Lo podemos calcular con el método corr.
# coeficiente de correlación
faithful.corr()
| eruptions | waiting | |
|---|---|---|
| eruptions | 1.000000 | 0.900811 |
| waiting | 0.900811 | 1.000000 |
Como podemos ver las dos variables tienen una correlación bastante alta, lo que sugiere que están íntimamente relacionadas; a la misma conclusión habíamos llegado al observar el diagrama de dispersión.
Resumen estadístico
Hasta aquí hemos calculado tanto las medidas de tendencia central como las medidas de dispersión una por una, pero ¿no sería más conveniente que con un simple comando podemos obtener un resumen estadístico con las principales medidas? Es por esto que Pandas nos ofrece el método describe, un comando para gobernarlos a todos!, el cual nos ofrece un resumen con las principales medidas estadísticas.
# resumen estadístico
faithful['eruptions'].describe()
count 272.000000
mean 3.487783
std 1.141371
min 1.600000
25% 2.162750
50% 4.000000
75% 4.454250
max 5.100000
Name: eruptions, dtype: float64
Siguiendo la misma línea; Seaborn nos ofrece la función pairplot que nos proporciona un resumen gráfico con histogramas y diagramas de dispersión de las variables de nuestro dataset.
par= sns.pairplot(faithful)
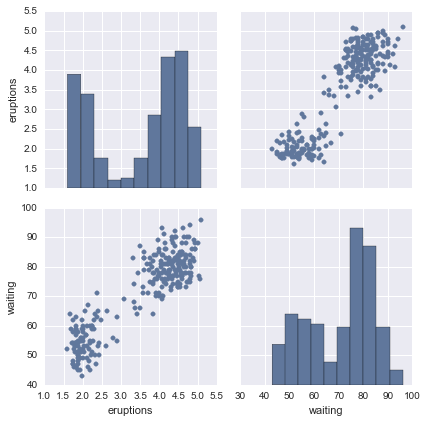
Con esto concluye este artículo; ahora ya deberían estar en condiciones de poder analizar tanto variables cuantitativas como variables categóricas. A practicar!
Saludos!
Este post fue escrito utilizando Jupyter notebook. Pueden descargar este notebook o ver su version estática en nbviewer.