Machine Learning con Python - Sobreajuste
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, Analisis de datos y Python. El contenido esta bajo la licencia BSD.

Introducción
Uno de los conceptos más importantes en Machine Learning es el overfitting o sobreajuste del modelo. Comprender como un modelo se ajusta a los datos es muy importante para entender las causas de baja precisión en las predicciones. Un modelo va a estar sobreajustado cuando vemos que se desempeña bien con los datos de entrenamiento, pero su precisión es notablemente más baja con los datos de evaluación; esto se debe a que el modelo ha memorizado los datos que ha visto y no pudo generalizar las reglas para predecir los datos que no ha visto. De aquí también la importancia de siempre contar con dos conjuntos de datos distintos, uno para entrenar el modelo y otro para evaluar su precisión; ya que si utilizamos el mismo dataset para las dos tareas, no tendríamos forma de determinar como el modelo se comporta con datos que nunca ha visto.
¿Cómo reconocer el sobreajuste?
En líneas generales el sobreajuste va a estar relacionado con la complejidad del modelo, mientras más complejidad le agreguemos, mayor va a ser la tendencia a sobreajustarse a los datos, ya que va a contar con mayor flexibilidad para realizar las predicciones y puede ser que los patrones que encuentre estén relacionados con el ruido (pequeños errores aleatorios) en los datos y no con la verdadera señal o relación subyacente.
No existe una regla general para establecer cual es el nivel ideal de complejidad que le podemos otorgar a nuestro modelo sin caer en el sobreajuste; pero podemos valernos de algunas herramientas analíticas para intentar entender como el modelo se ajusta a los datos y reconocer el sobreajuste. Veamos un ejemplo.
Árboles de Decisión y sobreajuste
Los Árboles de Decisión pueden ser muchas veces una herramienta muy precisa, pero también con mucha tendencia al sobreajuste. Para construir estos modelos aplicamos un procedimiento recursivo para encontrar los atributos que nos proporcionan más información sobre distintos subconjuntos de datos, cada vez más pequeños. Si aplicamos este procedimiento en forma reiterada, eventualmente podemos llegar a un árbol en el que cada hoja tenga una sola instancia de nuestra variable objetivo a clasificar. En este caso extremo, el Árbol de Decisión va a tener una pobre generalización y estar bastante sobreajustado; ya que cada instancia de los datos de entrenamiento va a encontrar el camino que lo lleve eventualmente a la hoja que lo contiene, alcanzando así una precisión del 100% con los datos de entrenamiento. Veamos un ejemplo sencillo con la ayuda de Python.
Ver Código
# <!-- collapse=True -->
# Importando las librerías que vamos a utilizar
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cross_validation import train_test_split
from sklearn.datasets import make_classification
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
import random; random.seed(1982)
# graficos incrustados
%matplotlib inline
# parametros esteticos de seaborn
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
# Ejemplo en python - árboles de decisión
# dummy data con 100 atributos y 2 clases
X, y = make_classification(10000, 100, n_informative=3, n_classes=2,
random_state=1982)
# separ los datos en train y eval
x_train, x_eval, y_train, y_eval = train_test_split(X, y, test_size=0.35,
train_size=0.65,
random_state=1982)
# creando el modelo sin control de profundidad, va a continuar hasta
# que todas las hojas sean puras
arbol = DecisionTreeClassifier(criterion='entropy')
# Ajustando el modelo
arbol.fit(x_train, y_train)
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
# precisión del modelo en datos de entrenamiento.
print("precisión entranamiento: {0: .2f}".format(
arbol.score(x_train, y_train)))
precisión entranamiento: 1.00
Logramos una precisión del 100 %, increíble, este modelo no se equivoca! deberíamos utilizarlo para jugar a la lotería y ver si ganamos algunos millones; o tal vez, no?. Veamos como se comporta con los datos de evaluación.
# precisión del modelo en datos de evaluación.
print("precisión evaluación: {0: .2f}".format(
arbol.score(x_eval, y_eval)))
precisión evaluación: 0.87
Ah, ahora nuestro modelo ya no se muestra tan preciso, esto se debe a que seguramente esta sobreajustado, ya que dejamos crecer el árbol hasta que cada hoja estuviera pura (es decir que solo contenga datos de una sola de las clases a predecir). Una alternativa para reducir el sobreajuste y ver si podemos lograr que generalice mejor y por tanto tenga más precisión para datos nunca vistos, es tratar de reducir la complejidad del modelo por medio de controlar la profundidad que puede alcanzar el Árbol de Decisión.
# profundidad del arbol de decisión.
arbol.tree_.max_depth
22
Este caso nuestro modelo tiene una profundidad de 22 nodos; veamos si reduciendo esa cantidad podemos mejorar la precisión en los datos de evaluación. Por ejemplo, pongamos un máximo de profundidad de tan solo 5 nodos.
# modelo dos, con control de profundiad de 5 nodos
arbol2 = DecisionTreeClassifier(criterion='entropy', max_depth=5)
# Ajustando el modelo
arbol2.fit(x_train, y_train)
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=5,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
# precisión del modelo en datos de entrenamiento.
print("precisión entranamiento: {0: .2f}".format(
arbol2.score(x_train, y_train)))
precisión entranamiento: 0.92
Ahora podemos ver que ya no tenemos un modelo con 100% de precisión en los datos de entrenamiento, sino que la precisión es bastante inferior, 92%, sin embargo si ahora medimos la precisión con los datos de evaluación vemos que la precisión es del 90%, 3 puntos por arriba de lo que habíamos conseguido con el primer modelo que nunca se equivocaba en los datos de entrenamiento.
# precisión del modelo en datos de evaluación.
print("precisión evaluación: {0: .2f}".format(
arbol2.score(x_eval, y_eval)))
precisión evaluación: 0.90
Esta diferencia se debe a que reducimos la complejidad del modelo para intentar ganar en generalización. También debemos tener en cuenta que si seguimos reduciendo la complejidad, podemos crear un modelo demasiado simple que en vez de estar sobreajustado puede tener un desempeño muy por debajo del que podría tener; podríamos decir que el modelo estaría infraajustado y tendría un alto nivel de sesgo. Para ayudarnos a encontrar el término medio entre la complejidad del modelo y su ajuste a los datos, podemos ayudarnos de herramientas gráficas. Por ejemplo podríamos crear diferentes modelos, con distintos grados de complejidad y luego graficar la precisión en función de la complejidad.
# Grafico de ajuste del árbol de decisión
train_prec = []
eval_prec = []
max_deep_list = list(range(3, 23))
for deep in max_deep_list:
arbol3 = DecisionTreeClassifier(criterion='entropy', max_depth=deep)
arbol3.fit(x_train, y_train)
train_prec.append(arbol3.score(x_train, y_train))
eval_prec.append(arbol3.score(x_eval, y_eval))
# graficar los resultados.
plt.plot(max_deep_list, train_prec, color='r', label='entrenamiento')
plt.plot(max_deep_list, eval_prec, color='b', label='evaluacion')
plt.title('Grafico de ajuste arbol de decision')
plt.legend()
plt.ylabel('precision')
plt.xlabel('cant de nodos')
plt.show()
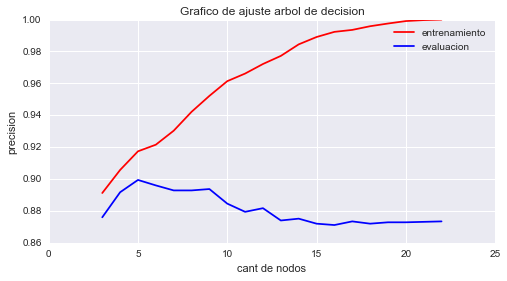
El gráfico que acabamos de construir se llama gráfico de ajuste y muestra la precisión del modelo en función de su complejidad. En nuestro ejemplo, podemos ver que el punto con mayor precisión, en los datos de evaluación, lo obtenemos con un nivel de profundidad de aproximadamente 5 nodos; a partir de allí el modelo pierde en generalización y comienza a estar sobreajustado. También podemos crear un gráfico similar con la ayuda de Scikit-learn, utilizando validation_curve.
# utilizando validation curve de sklearn
from sklearn.learning_curve import validation_curve
train_prec, eval_prec = validation_curve(estimator=arbol, X=x_train,
y=y_train, param_name='max_depth',
param_range=max_deep_list, cv=5)
train_mean = np.mean(train_prec, axis=1)
train_std = np.std(train_prec, axis=1)
test_mean = np.mean(eval_prec, axis=1)
test_std = np.std(eval_prec, axis=1)
# graficando las curvas
plt.plot(max_deep_list, train_mean, color='r', marker='o', markersize=5,
label='entrenamiento')
plt.fill_between(max_deep_list, train_mean + train_std,
train_mean - train_std, alpha=0.15, color='r')
plt.plot(max_deep_list, test_mean, color='b', linestyle='--',
marker='s', markersize=5, label='evaluacion')
plt.fill_between(max_deep_list, test_mean + test_std,
test_mean - test_std, alpha=0.15, color='b')
plt.grid()
plt.legend(loc='center right')
plt.xlabel('Cant de nodos')
plt.ylabel('Precision')
plt.show()
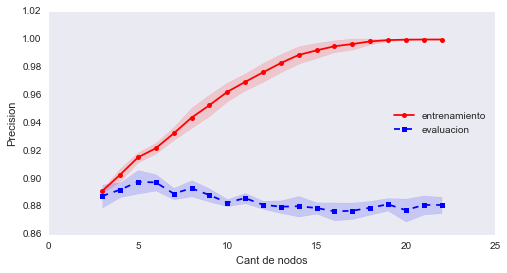
En este gráfico, también podemos ver que nuestro modelo tiene bastante varianza, representada por el área esfumada.
Métodos para reducir el Sobreajuste
Algunas de las técnicas que podemos utilizar para reducir el Sobreajuste, son:
- Utilizar validación cruzada.
- Recolectar más datos.
- Introducir una penalización a la complejidad con alguna técnica de regularización.
- Optimizar los parámetros del modelo con grid search.
- Reducir la dimensión de los datos.
- Aplicar técnicas de selección de atributos.
- Utilizar modelos ensamblados.
Veamos algunos ejemplos.
Validación cruzada
La validación cruzada se inicia mediante el fraccionamiento de un conjunto de datos en un número \(k\) de particiones (generalmente entre 5 y 10) llamadas pliegues. La validación cruzada luego itera entre los datos de evaluación y entrenamiento \(k\) veces, de un modo particular. En cada iteración de la validación cruzada, un pliegue diferente se elige como los datos de evaluación. En esta iteración, los otros pliegues \(k-1\) se combinan para formar los datos de entrenamiento. Por lo tanto, en cada iteración tenemos \((k-1) / k\) de los datos utilizados para el entrenamiento y \(1 / k\) utilizado para la evaluación. Cada iteración produce un modelo, y por lo tanto una estimación del rendimiento de la generalización, por ejemplo, una estimación de la precisión. Una vez finalizada la validación cruzada, todos los ejemplos se han utilizado sólo una vez para evaluar pero \(k -1\) veces para entrenar. En este punto tenemos estimaciones de rendimiento de todos los pliegues y podemos calcular la media y la desviación estándar de la precisión del modelo. Veamos un ejemplo

# Ejemplo cross-validation
from sklearn import cross_validation
# creando pliegues
kpliegues = cross_validation.StratifiedKFold(y=y_train, n_folds=10,
random_state=2016)
# iterando entre los plieges
precision = []
for k, (train, test) in enumerate(kpliegues):
arbol2.fit(x_train[train], y_train[train])
score = arbol2.score(x_train[test], y_train[test])
precision.append(score)
print('Pliegue: {0:}, Dist Clase: {1:}, Prec: {2:.3f}'.format(k+1,
np.bincount(y_train[train]), score))
# imprimir promedio y desvio estandar
print('Precision promedio: {0: .3f} +/- {1: .3f}'.format(np.mean(precision),
np.std(precision)))
Pliegue: 1, Dist Clase: [2918 2931], Prec: 0.909
Pliegue: 2, Dist Clase: [2918 2931], Prec: 0.896
Pliegue: 3, Dist Clase: [2918 2931], Prec: 0.897
Pliegue: 4, Dist Clase: [2919 2931], Prec: 0.920
Pliegue: 5, Dist Clase: [2919 2931], Prec: 0.895
Pliegue: 6, Dist Clase: [2919 2931], Prec: 0.912
Pliegue: 7, Dist Clase: [2919 2931], Prec: 0.871
Pliegue: 8, Dist Clase: [2919 2932], Prec: 0.906
Pliegue: 9, Dist Clase: [2919 2932], Prec: 0.884
Pliegue: 10, Dist Clase: [2919 2932], Prec: 0.891
Precision promedio: 0.898 +/- 0.014
En este ejemplo, utilizamos el iterador StratifiedKFold que nos proporciona Scikit-learn. Este iterador es una versión mejorada de la validación cruzada, ya que cada pliegue va a estar estratificado para mantener las proporciones entre las clases del conjunto de datos original, lo que suele dar mejores estimaciones del sesgo y la varianza del modelo. También podríamos utilizar cross_val_score que ya nos proporciona los resultados de la precisión que tuvo el modelo en cada pliegue.
# Ejemplo con cross_val_score
precision = cross_validation.cross_val_score(estimator=arbol2,
X=x_train, y=y_train,
cv=10, n_jobs=-1)
print('precisiones: {}'.format(precision))
print('Precision promedio: {0: .3f} +/- {1: .3f}'.format(np.mean(precision),
np.std(precision)))
precisiones: [ 0.906298 0.89708141 0.89708141 0.91846154 0.89538462 0.91230769
0.87076923 0.90755008 0.8844376 0.89060092]
Precision promedio: 0.898 +/- 0.013
Más datos y curvas de aprendizaje
Muchas veces, reducir el Sobreajuste es tan fácil como conseguir más datos, dame más datos y te predeciré el futuro!. Aunque en la vida real nunca es una tarea tan sencilla conseguir más datos. Otra herramienta analítica que nos ayuda a entender como reducimos el Sobreajuste con la ayuda de más datos, son las curvas de aprendizaje, las cuales grafican la precisión en función del tamaño de los datos de entrenamiento. Veamos como podemos graficarlas con la ayuda de Python.

# Ejemplo Curvas de aprendizaje
from sklearn.learning_curve import learning_curve
train_sizes, train_scores, test_scores = learning_curve(estimator=arbol2,
X=x_train, y=y_train,
train_sizes=np.linspace(0.1, 1.0, 10), cv=10,
n_jobs=-1)
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# graficando las curvas
plt.plot(train_sizes, train_mean, color='r', marker='o', markersize=5,
label='entrenamiento')
plt.fill_between(train_sizes, train_mean + train_std,
train_mean - train_std, alpha=0.15, color='r')
plt.plot(train_sizes, test_mean, color='b', linestyle='--',
marker='s', markersize=5, label='evaluacion')
plt.fill_between(train_sizes, test_mean + test_std,
test_mean - test_std, alpha=0.15, color='b')
plt.grid()
plt.title('Curva de aprendizaje')
plt.legend(loc='upper right')
plt.xlabel('Cant de ejemplos de entrenamiento')
plt.ylabel('Precision')
plt.show()
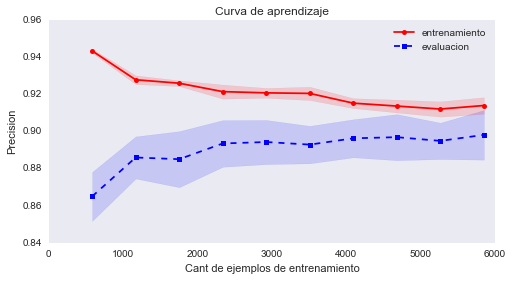
En este gráfico podemos ver claramente como con pocos datos la precisión entre los datos de entrenamiento y los de evaluación son muy distintas y luego a medida que la cantidad de datos va aumentando, el modelo puede generalizar mucho mejor y las precisiones se comienzan a emparejar. Este gráfico también puede ser importante a la hora de decidir invertir en la obtención de más datos, ya que por ejemplo nos indica que a partir las 2500 muestras, el modelo ya no gana mucha más precisión a pesar de obtener más datos.
Optimización de parámetros con Grid Search
La mayoría de los modelos de Machine Learning cuentan con varios parámetros para ajustar su comportamiento, por lo tanto otra alternativa que tenemos para reducir el Sobreajuste es optimizar estos parámetros por medio de un proceso conocido como grid search e intentar encontrar la combinación ideal que nos proporcione mayor precisión. El enfoque que utiliza grid search es bastante simple, se trata de una búsqueda exhaustiva por el paradigma de fuerza bruta en el que se especifica una lista de valores para diferentes parámetros, y la computadora evalúa el rendimiento del modelo para cada combinación de éstos parámetros para obtener el conjunto óptimo que nos brinda el mayor rendimiento.
Veamos un ejemplo utilizando un modelo de SVM o Máquinas de vectores de soporte, la idea va a ser optimizar los parámetros gamma y C de este modelo. El parámetro gamma define cuan lejos llega la influencia de un solo ejemplo de entrenamiento, con valores bajos que significan “lejos” y los valores altos significan “cerca”. El parámetro C es el que establece la penalización por error en la clasificación un valor bajo de este parámetro hace que la superficie de decisión sea más lisa, mientras que un valor alto tiene como objetivo que todos los ejemplos se clasifiquen correctamente, dándole más libertad al modelo para elegir más ejemplos como vectores de soporte. Tengan en cuenta que como todo proceso por fuerza bruta, puede tomar bastante tiempo según la cantidad de parámetros que utilicemos para la optimización.
# Ejemplo de grid search con SVM.
from sklearn.grid_search import GridSearchCV
# creación del modelo
svm = SVC(random_state=1982)
# rango de parametros
rango_C = np.logspace(-2, 10, 10)
rango_gamma = np.logspace(-9, 3, 10)
param_grid = dict(gamma=rango_gamma, C=rango_C)
# crear grid search
gs = GridSearchCV(estimator=svm, param_grid=param_grid, scoring='accuracy',
cv=5,n_jobs=-1)
# comenzar el ajuste
gs = gs.fit(x_train, y_train)
# imprimir resultados
print(gs.best_score_)
print(gs.best_params_)
0.870461538462
{'C': 4.6415888336127775, 'gamma': 0.0046415888336127729}
# utilizando el mejor modelo
mejor_modelo = gs.best_estimator_
mejor_modelo.fit(x_train, y_train)
print('Precisión: {0:.3f}'.format(mejor_modelo.score(x_eval, y_eval)))
Precisión: 0.864
En este ejemplo, primero utilizamos el objeto GridSearchCV que nos permite realizar grid search junto con validación cruzada, luego comenzamos a ajustar el modelo con las diferentes combinaciones de los valores de los parámetros gamma y C. Finalmente imprimimos el mejor resultado de precisión y los valores de los parámetros que utilizamos para obtenerlos; por último utilizamos este mejor modelo para realizar las predicciones con los datos de evaluación. Podemos ver que la precisión que obtuvimos con los datos de evaluación es casi idéntica a la que nos indicó grid search, lo que indica que el modelo generaliza muy bien.
Aquí termina este artículo, sobre la selección de atributos, pueden visitar el artículo que dedique a ese tema en este link; en cuando a modelos ensamblados y reducción de dimensiones de los datos, espero escribir sobre esos temas en artículos futuros, no se los pierdan!
Gracias por visitar el blog y saludos!
Este post fue escrito utilizando IPython notebook. Pueden descargar este notebook o ver su version estática en nbviewer.