Boosting en Machine Learning con Python
Esta notebook fue creada originalmente como un blog post por Raúl E. López Briega en Matemáticas, Analisis de datos y Python. El contenido esta bajo la licencia BSD.

“La opinión de toda una multitud es siempre más creíble que la de una minoría.”
Introducción
La meta de construir sistemas que puedan adaptarse a sus entornos y aprender de su experiencia ha atraído a investigadores de muchos campos, como la Informática, Matemáticas, Física, Neurociencia y la Ciencia cognitiva. Intuitivamente, para que un algoritmo de aprendizaje sea efectivo y preciso en sus predicciones, debería reunir tres condiciones básicas:
- Debería ser entrenado con suficientes datos de entrenamiento.
- Sus resultados deberían ajustarse bastante bien a los ejemplos de entrenamiento (lo que significaría tener una tasa de error baja).
- Debería ser lo suficientemente “simple”. Esta última condición, que las reglas más simples suelen ser las mejores, se conoce a menudo con el nombre de “La navaja de Occam”.
Muchos algoritmos se han creado y existen aún muchos por descubrir; pero unos de los que ha ganado mucha atracción en los últimos años por su simpleza y su gran éxito en competencias como kraggle, son los algoritmos de Boosting.
¿Qué es Boosting?
Boosting es un enfoque de Machine Learning basado en la idea de crear una regla de predicción altamente precisa combinando muchas reglas relativamente débiles e imprecisas. Una teoría notablemente rica ha evolucionado en torno al Boosting, con conexiones a una amplia gama de ramas de la ciencia, incluyendo estadísticas, teoría de juegos, optimización convexa y geometría de la información. Los algoritmos de Boosting han tenido éxito práctico con aplicaciones, por ejemplo, en biología, visión y procesamiento del lenguaje natural. En varios momentos de su historia, el Boosting ha sido objeto de controversia por el misterio y la paradoja que parece presentar. El Boosting asume la disponibilidad de un algoritmo de aprendizaje base o débil que, dado ejemplos de entrenamiento etiquetados, produce un clasificador base o débil. El objetivo de Boosting es el de mejorar el rendimiento del algoritmo de aprendizaje al tratarlo como una “caja negra” que se puede llamar repetidamente, como una subrutina. Si bien el algoritmo de aprendizaje base puede ser rudimentario y moderadamente inexacto, no es del todo trivial ni poco informativo y debe obtener resultados mejores a los que se podrían obtener en forma aleatoria. La idea fundamental detrás de Boosting es elegir conjuntos de entrenamiento para el algoritmo de aprendizaje base de tal manera que lo obligue a inferir algo nuevo sobre los datos cada vez que se lo llame. Uno de los primeros algoritmos de Boosting en tener éxito en problemas de clasificación binaria fue AdaBoost.
AdaBoost
AdaBoost es la abreviatura de adaptive boosting, es un algoritmo que puede ser utilizado junto con otros algoritmos de aprendizaje para mejorar su rendimiento. AdaBoost funciona eligiendo un algoritmo base (por ejemplo árboles de decisión) y mejorándolo iterativamente al tomar en cuenta los casos incorrectamente clasificados en el conjunto de entrenamiento.
En AdaBoost asignamos pesos iguales a todos los ejemplos de entrenamiento y elegimos un algoritmo base. En cada paso de iteración, aplicamos el algoritmo base al conjunto de entrenamiento y aumentamos los pesos de los ejemplos incorrectamente clasificados. Iteramos n veces, cada vez aplicando el algoritmo base en el conjunto de entrenamiento con pesos actualizados. El modelo final es la suma ponderada de los resultados de los n algoritmos base. AdaBoost en conjunto con árboles de decisión se ha mostrado sumamente efectivo en varios problemas de Machine Learning. Veamos un ejemplo en Python.
Ver Código
# <!-- collapse=True -->
# Importando las librerías que vamos a utilizar
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
import graphviz
import xgboost as xgb
# graficos incrustados
%matplotlib inline
# parametros esteticos de seaborn
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
# Utilzando el dataset breast cancer
cancer = load_breast_cancer()
# dataset en formato tabular
pd.DataFrame(data=cancer.data,
columns=cancer.feature_names).head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 |
5 rows × 30 columns
# Separando los datos en sets de entrenamiento y evaluación
X_train, X_test, y_train, y_test = train_test_split(cancer.data,
cancer.target, random_state=1)
# Armando un simple arbol de decisión
tree = DecisionTreeClassifier(max_depth=2, random_state=0)
tree.fit(X_train, y_train)
print('Precisión modelo inicial train/test {0:.3f}/{1:.3f}'
.format(tree.score(X_train, y_train), tree.score(X_test, y_test)))
Precisión modelo inicial train/test 0.962/0.888
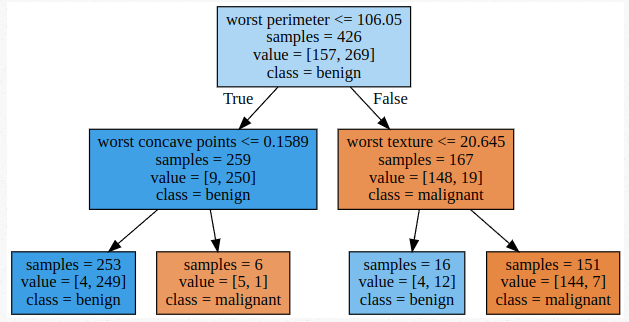
# Dibujando el modelo
export_graphviz(tree, out_file="tree.dot", class_names=["malignant", "benign"],
feature_names=cancer.feature_names, impurity=False, filled=True)
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
# Utilizando AdaBoost para aumentar la precisión
ada = AdaBoostClassifier(base_estimator=tree, n_estimators=500,
learning_rate=1.5, random_state=1)
# Ajustando los datos
ada = ada.fit(X_train, y_train)
# Imprimir la precisión.
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train, y_train_pred)
ada_test = accuracy_score(y_test, y_test_pred)
print('Precisión modelo con AdaBoost train/test {0:.3f}/{1:.3f}'
.format(ada_train, ada_test))
Precisión modelo con AdaBoost train/test 1.000/0.965
Para este ejemplo utilizamos el conjunto de datos breast cancer que ya viene en cargado en scikit-learn; la idea es clasificar casos de cáncer de pecho según varios atributos de los tumores.
En primer lugar, creamos un clasificador simple, un árbol de decisión de hasta dos niveles de profundidad. Este clasificador tuvo un rendimiento bastante bueno, logrando una precisión del 96% con los datos de entrenamiento y del 89% con los datos de evaluación.
Luego aplicamos AdaBoost sobre el mismo modelo para mejorar la precisión. Vemos que el modelo con AdaBoost logra una precisión del 100% en los datos de entrenamiento y del 96% en los datos de evaluación. Debemos tener en cuenta que una precisión del 100% sobre los datos de entrenamiento, puede ser un indicio de que el modelo tal vez este sobreajustado. El sobreajuste es uno de los riesgo que suele traer aparejado la utilización de las técnicas de Boosting.
A partir del éxito inicial de AdaBoost, las técnicas de Boosting fueron evolucionando hacia un modelo estadístico más generalizado, tratando el problema como un caso de optimización numérica en dónde el objetivo es minimizar la función de perdida del modelo mediante la adición de los algoritmos de aprendizaje débiles utilizando un procedimiento de optimización del tipo de gradiente descendiente. Esta generalización permitió utilizar funciones arbitrarias de pérdida diferenciables, ampliando la técnica más allá de los problemas de clasificación binaria hacia problemas de regresión y de clasificación multi-variable. Esta nueva familia de algoritmos de Boosting se conocen bajo el nombre de Gradient boosting.
Gradient Boosting
El Gradient boosting implica tres elementos:
- Una función de perdida a optimizar .
- Un algoritmo de aprendizaje débil para hacer las predicciones.
- Un modelo aditivo para añadir los algoritmos de aprendizaje débiles que minimizan la función de perdida.
Función de pérdida
La función de perdida utilizada va a depender del tipo de problema al que nos enfrentamos. La principal característica que debe poseer, es que sea diferenciable. Existen varias funciones de pérdida estándar. Por ejemplo, para problemas de regresión podemos utilizar un error cuadrático y para problemas de clasificación podemos utilizar una pérdida logarítmica o una entropía cruzada.
Algoritmo de aprendizaje débil
El algoritmo de aprendizaje débil que se utiliza en el Gradient boosting es el de árboles de decisión. Específicamente se usan árboles de regresión que producen valores reales para las divisiones y cuya salida se puede sumar, permitiendo que los resultados de los modelos subsiguientes sean agregados y corrijan los errores promediando las predicciones. Es común restringir a los árboles de decisión de manera específica para asegurarnos que el algoritmo permanezca débil. Se suelen restringir el número máximo de capas, nodos, divisiones u hojas.
Modelo aditivo
Los árboles de decisión son agregados de a uno a la vez, y los árboles existentes en el modelo no cambian. Para determinar los parámetros que tendrán cada uno de los árboles de decisión que son agregados al modelo se utiliza un procedimiento de gradiente descendiente que minimizará la función de perdida. De esta forma se van agregando árboles con distintos parámetros de forma tal que la combinación de ellos minimiza la pérdida del modelo y mejora la predicción.
Árboles de decisión con Gradient boosting es uno de los modelos más poderosos y más utilizados para problemas de aprendizaje supervisado. Su principal inconveniente es que requieren un ajuste cuidadoso de los parámetros y puede requerir mucho tiempo de entrenamiento. Al igual que otros modelos basados en árboles, el algoritmo funciona y escala bien con una mezcla de características binarias y continuas. Asimismo, también arrastra el problema de los árboles de decisión en los casos en que los datos están dispersos y tienen una alta dimensionalidad. Veamos un ejemplo con scikit-learn utilizando los mismos datos de breast cancer del ejemplo anterior.
# Armando el modelo con parametro max_depth
gbrt = GradientBoostingClassifier(random_state=0, n_estimators=500,
max_depth=1, learning_rate=0.01)
# Ajustando el modelo
gbrt.fit(X_train, y_train)
print('Precisión Gradient Boosting train/test {0:.3f}/{1:.3f}'
.format(gbrt.score(X_train, y_train), gbrt.score(X_test, y_test)))
Precisión Gradient Boosting train/test 0.991/0.937
# Graficando la importancia de cada atributo
n_atributos = cancer.data.shape[1]
plt.barh(range(n_atributos), gbrt.feature_importances_, align='center')
plt.yticks(np.arange(n_atributos), cancer.feature_names)
plt.xlabel("Importancia de atributo")
plt.ylabel("Atributo")
plt.show();
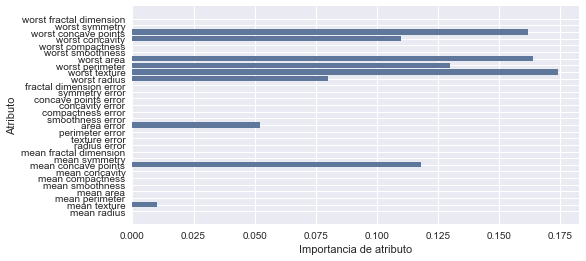
Los principales parámetros de los modelos de árboles de decisión con Gradient boosting son el número de árboles, n_estimators, y la tasa de aprendizaje, learning_rate, que controla el grado en que a cada árbol se le permite corregir los errores de los árboles anteriores. Estos dos parámetros están altamente interconectados en el sentido de que si bajamos el valor en la tasa de aprendizaje vamos a necesitar un número mayor de árboles para construir un modelo de complejidad similar. Como podemos ver en el ejemplo, aplicando Gradient boosting con árboles de tan solo un nivel de profundidad, logramos una precisión del 99 % sobre los datos de entrenamiento y del 93 % sobre los datos de evaluación.
Si deseamos aplicar el algoritmo de Gradient boosting a un problema de gran escala, entonces la librería que sobresale por su facilidad de utilización y rendimiento es XGBoost.
XGBoost
XGBoost significa eXtreme Gradient Boosting. Es el algoritmo que ha estado dominando recientemente los problemas Machine learning y las competiciones de Kaggle con datos estructurados o tabulares. XGBoost es una implementación de árboles de decisión con Gradient boosting diseñada para minimizar la velocidad de ejecución y maximizar el rendimiento. Posee una interface para varios lenguajes de programación, entre los que se incluyen Python, R, Julia y Scala.
Internamente, XGBoost representa todos los problemas como un caso de modelado predictivo de regresión que sólo toma valores numéricos como entrada. Si nuestros datos están en un formato diferente, primero vamos a tener que transformarlos para poder hacer uso de todo el poder de esta librería. El hecho de trabajar sólo con datos numéricos es lo que hace que esta librería sea tan eficiente.
Veamos como la podemos utilizar en Python con un ejemplo. Para este caso vamos a trabajar con el dataset UCI breast-cancer, el cual contiene todos datos categóricos que vamos a tener que transformar. Este conjunto de datos describe los detalles técnicos de las biopsias de cáncer de mama y la tarea de predicción es predecir si el paciente tiene o no una recurrencia del cáncer, o no.
# Ejemplo de XGBoost
# cargando los datos
cancer2 = pd.read_csv('https://relopezbriega.github.io/downloads/datasets-uci-breast-cancer.csv')
cancer2.head()
| Unnamed: 0 | age | menopause | tumor-size | inv-nodes | node-caps | deg-malig | breast | breast-quad | irradiat | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | '40-49' | 'premeno' | '15-19' | '0-2' | 'yes' | '3' | 'right' | 'left_up' | 'no' | 'recurrence-events' |
| 1 | 1 | '50-59' | 'ge40' | '15-19' | '0-2' | 'no' | '1' | 'right' | 'central' | 'no' | 'no-recurrence-events' |
| 2 | 2 | '50-59' | 'ge40' | '35-39' | '0-2' | 'no' | '2' | 'left' | 'left_low' | 'no' | 'recurrence-events' |
| 3 | 3 | '40-49' | 'premeno' | '35-39' | '0-2' | 'yes' | '3' | 'right' | 'left_low' | 'yes' | 'no-recurrence-events' |
| 4 | 4 | '40-49' | 'premeno' | '30-34' | '3-5' | 'yes' | '2' | 'left' | 'right_up' | 'no' | 'recurrence-events' |
# Divido los datos en data y target.
cancer_data = cancer2.values
cancer2.data = cancer_data[:,0:9]
cancer2.data = cancer2.data.astype(str)
cancer2.target = cancer_data[:,9]
cancer2.data.shape
(286, 9)
# Aplico el enconding para transformar los datos de entrada a valores
# numericos utilizando OneHotEncoder
encoded_data = None
for i in range(0, cancer2.data.shape[1]):
label_encoder = LabelEncoder()
feature = label_encoder.fit_transform(cancer2.data[:,i])
feature = feature.reshape(cancer2.data.shape[0], 1)
onehot_encoder = OneHotEncoder(sparse=False)
feature = onehot_encoder.fit_transform(feature)
if encoded_data is None:
encoded_data = feature
else:
encoded_data = np.concatenate((encoded_data, feature), axis=1)
# Aplico LaberEncoder a los valores de la variable target.
label_encoder = LabelEncoder()
label_encoder = label_encoder.fit(cancer2.target)
encoded_y = label_encoder.transform(cancer2.target)
# Separando los datos en sets de entrenamiento y evaluación
X_train, X_test, y_train, y_test = train_test_split(encoded_data,
encoded_y, random_state=1)
# Construyo el modelo y ajusto los datos.
modelo = xgb.XGBClassifier()
modelo.fit(X_train, y_train)
# Realizo las predicciones
y_pred = modelo.predict(X_train)
predicciones = [round(value) for value in y_pred]
# Evalúo las predicciones
precision_train = accuracy_score(y_train, predicciones)
# Repito el proceso con datos de evaluacion
y_pred = modelo.predict(X_test)
predicciones = [round(value) for value in y_pred]
# Evalúo las predicciones
precision_test = accuracy_score(y_test, predicciones)
print(modelo)
print('Precisión xgboost train/test {0:.3f}/{1:.3f}'
.format(precision_train, precision_test))
XGBClassifier(base_score=0.5, colsample_bylevel=1, colsample_bytree=1,
gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=3,
min_child_weight=1, missing=None, n_estimators=100, nthread=-1,
objective='binary:logistic', reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, seed=0, silent=True, subsample=1)
Precisión xgboost train/test 0.879/0.694
En este ejemplo logramos una precisión de 88 % con los datos de entrenamiento y del 69 % con los datos de evaluación.
Con esto termina este artículo. Espero les haya sido de utilidad y puedan explorar todo el poder predictivo de XGBoost. Asimismo, otra implementación de Gradient boosting que deberíamos tener en cuenta ya que también ha obtenido muy buenos resultados en términos de precisión y rendimiento es LightGBM, que forma parte del Distributed Machine Learning Toolkit de Microsoft.
Saludos!
Este post fue escrito por Raúl e. López Briega utilizando Jupyter notebook. Pueden descargar este notebook o ver su version estática en nbviewer.